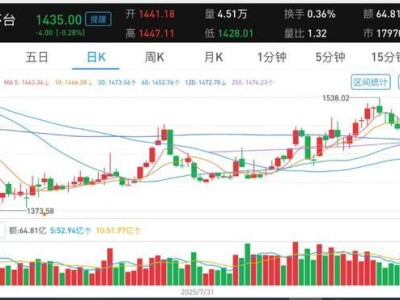
DeepMind近日推出了專為機器人與具身智能設計的Gemini Robotics 1.5系列模型,為實體世界中的智能體賦予了更接近人類的思考與行動能力。這一系列包含Gemini Robotics 1.5與Gemini Robotics-ER 1.5兩款模型,分別聚焦于動作執行與環境推理,共同構建出支持復雜任務完成的智能框架。
作為視覺-語言-動作模型的代表,Gemini Robotics 1.5能夠將視覺信息與語言指令轉化為精準的機械動作。例如,在垃圾分類任務中,機器人Aloha通過分析物品特征并參考舊金山分類標準,自主將物品分配至堆肥、回收或垃圾容器。而在另一場景中,Apollo機器人不僅完成了打包針織帽的任務,還主動查詢倫敦天氣并添加雨傘,展現了多步驟規劃與環境適應能力。
Gemini Robotics-ER 1.5則側重于物理世界的邏輯推理與工具調用。該模型支持自然語言交互,可評估任務進度并調用谷歌搜索等外部資源。在實際應用中,它通過生成自然語言指令指導Gemini Robotics 1.5執行動作,同時利用空間理解能力優化任務路徑。例如,在復雜環境中,ER 1.5能分解任務步驟并動態調整策略,確保高效完成目標。
兩款模型均基于Gemini核心架構開發,通過針對性數據集微調實現功能分化。協同工作時,它們顯著提升了機器人對長周期任務的處理能力。例如,在分類水果任務中,機器人需感知顏色、分析空間關系并逐步操作;在洗衣分類場景中,Apollo通過鏈式規劃調整抓取姿勢,甚至對臨時干擾作出即時反應。
跨具身學習能力是該系列的另一突破。傳統模型需針對不同機器人形態重新訓練,而Gemini Robotics 1.5支持動作遷移。實驗中,Apollo通過遷移Aloha在衣柜場景的經驗,成功完成開門、取衣等陌生動作。這種能力使得物流、零售等領域的機器人可共享學習成果,加速通用技術落地。
在技術實現上,Gemini Robotics-ER 1.5首次將具身推理優化引入思維模型。其支持物體檢測、軌跡預測、任務進度評估等功能,在學術與內部測試中均達到領先水平。例如,在分割掩碼任務中,模型可精準識別物體邊界;在任務成功檢測中,能實時反饋操作結果并調整策略。
這一系列模型的推出,標志著機器人從“指令執行”向“自主決策”的跨越。通過結合環境感知、邏輯推理與動作執行,智能體得以在復雜場景中完成多步驟任務。隨著跨具身學習技術的成熟,未來不同形態的機器人或將實現知識共享,推動通用機器人技術的規模化應用。