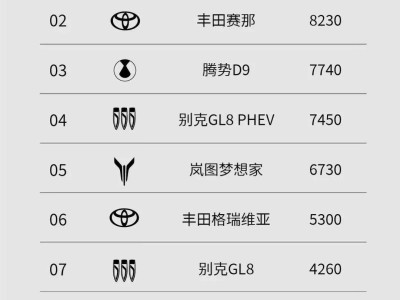
中國科學院計算技術研究所的研究團隊在NeurIPS 2025會議上發布了一項突破性成果——SpaceServe架構,該架構首次將大語言模型(LLM)推理中的并行-解碼(P/D)分離技術擴展至多模態場景,通過創新的“空分復用”機制徹底解決了多模態大語言模型(MLLM)推理中的行頭阻塞問題。
隨著MLLM在圖像理解、視頻分析等高分辨率任務中的廣泛應用,其推理流程中的多模態編碼階段逐漸成為性能瓶頸。傳統系統如vLLM采用“時間復用”策略,即GPU需先完成視覺或音頻編碼任務后,才能切換至文本解碼任務。這種設計在高并發場景下會引發嚴重問題:一個高分辨率圖像的編碼可能耗時數百毫秒,導致所有等待生成文本的解碼請求被迫阻塞,造成解碼器“饑餓”,輸出token耗時(TPOT)隨請求量激增而急劇上升,系統吞吐量大幅下降。
研究團隊提出的SpaceServe架構通過“空分復用”技術,將傳統的時間串行執行模式轉變為空間并行執行模式。定量分析顯示,視覺編碼器具有計算密集、內存帶寬需求低的特點,而文本解碼器則內存密集、高度依賴HBM帶寬存儲KV Cache。二者資源需求互補,卻在時間復用架構下被迫串行執行,導致GPU資源浪費。SpaceServe的核心創新在于將編碼器與解碼器解耦,并利用現代GPU的細粒度流式多處理器(SM)分區能力,實現二者在同一GPU上的并發執行。
該架構包含三大關鍵技術:首先,通過EPD(Encoder-Prefill-Decode)三階段邏輯解耦與物理共置,將多模態編碼器從共享文本解碼器中完全分離,支持獨立調度;其次,采用TWSRFT(Time-Window Shortest Remaining Work First)編碼器調度策略,按剩余工作量最短優先原則批處理編碼請求,避免大圖阻塞小圖,平滑解碼器輸入流;最后,開發基于資源利用曲線的動態分配運行時(Space Inference Runtime),離線構建資源-效用曲線,在線根據請求元數據動態分配SM計算單元,最小化端到端延遲。
在Qwen2-VL系列模型(2B–72B)上的實測數據顯示,SpaceServe顯著優于傳統vLLMv1系統。當請求率增加時,vLLM的TPOT從101ms急劇惡化至365ms,而SpaceServe僅從8.85ms微增至12.62ms。根本原因在于,vLLM中編碼器獨占GPU時解碼器無法推進,而SpaceServe通過空分復用使解碼器在編碼器運行期間持續生成token,徹底解耦了執行流程。
與NVIDIA MPS(Multi-Process Service)方案的對比進一步驗證了SpaceServe的優勢。在10 RPS(每秒請求數)條件下,MPS版本的TPOT為132ms,而SpaceServe通過細粒度SM分區將延遲降至40.68ms,提速3.3倍。這是因為MPS僅在進程級隔離資源,編碼器與解碼器仍會爭搶同一SM內的寄存器、L1緩存等資源,導致緩存污染與執行效率下降。而SpaceServe通過SM級物理分區實現了真正的資源隔離,最大化各自執行效率。
這項研究無需修改現有模型結構,即可兼容Qwen2-VL、Kimi-VL等主流MLLM,且代碼已開源,有望集成至vLLM、SGLang等框架,推動多模態服務的高效落地。值得注意的是,SpaceServe主要優化穩態吞吐(TPOT),對首token延遲(TTFT)影響有限,這與設計目標一致——聚焦于解碼器的持續高吞吐,而非單次編碼加速。
項目地址:https://github.com/gofreelee/SpaceServe