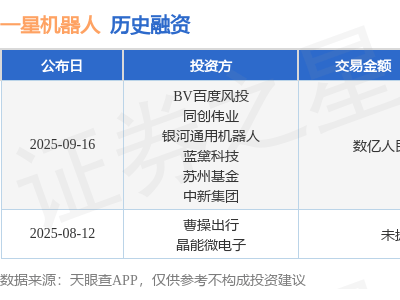
一場(chǎng)被稱為“人類終極測(cè)試”的AI能力評(píng)估引發(fā)全球科技界震動(dòng)。這項(xiàng)由全球50國(guó)近千名學(xué)者共同發(fā)起的挑戰(zhàn),通過(guò)2500道涵蓋數(shù)學(xué)、物理、生物、法律等領(lǐng)域的博士級(jí)難題,首次系統(tǒng)性揭示了當(dāng)前頂尖AI系統(tǒng)在專業(yè)學(xué)術(shù)領(lǐng)域的真實(shí)局限。令人驚訝的是,即便是GPT-4o、Claude 3.5等最強(qiáng)模型,在面對(duì)人類專家設(shè)計(jì)的“地獄級(jí)”考題時(shí),平均準(zhǔn)確率不足5%,展現(xiàn)出AI認(rèn)知能力與人類專家間的巨大鴻溝。
研究團(tuán)隊(duì)獨(dú)創(chuàng)的“三重篩選機(jī)制”確保了測(cè)試的嚴(yán)苛性。來(lái)自斯坦福大學(xué)、Scale AI等機(jī)構(gòu)的學(xué)者首先要求每位專家提交原創(chuàng)題目,這些題目必須通過(guò)當(dāng)前最強(qiáng)AI模型的測(cè)試——若任何模型能正確解答,該題將被淘汰。經(jīng)過(guò)7萬(wàn)次AI預(yù)測(cè)試和兩輪人工審核,最終2500道題目從1.3萬(wàn)份候選題中脫穎而出,其中14%的題目還包含復(fù)雜圖表或?qū)嶒?yàn)數(shù)據(jù),專門考驗(yàn)AI的多模態(tài)理解能力。
在數(shù)學(xué)領(lǐng)域,AI的表現(xiàn)暴露出根本性缺陷。盡管計(jì)算機(jī)本應(yīng)擅長(zhǎng)計(jì)算,但面對(duì)需要數(shù)學(xué)直覺(jué)的前沿問(wèn)題(如拓?fù)鋵W(xué)證明、數(shù)論猜想)時(shí),最強(qiáng)模型準(zhǔn)確率僅2.7%。研究團(tuán)隊(duì)形象比喻:普通數(shù)學(xué)題如同按食譜做菜,而專家級(jí)問(wèn)題則要求廚師用有限食材創(chuàng)造全新菜式。這種對(duì)數(shù)學(xué)本質(zhì)的理解,恰恰是當(dāng)前AI最欠缺的能力。
跨學(xué)科表現(xiàn)差異揭示AI認(rèn)知短板。生物醫(yī)學(xué)題目中,AI憑借模式識(shí)別優(yōu)勢(shì)取得10%準(zhǔn)確率,但仍遠(yuǎn)低于人類專家水平;物理問(wèn)題需要空間想象與規(guī)律抽象,AI表現(xiàn)介于數(shù)學(xué)與生物之間;而人文社科領(lǐng)域雖看似適合語(yǔ)言模型,卻因需要批判思維與文化洞察力,導(dǎo)致AI準(zhǔn)確率未現(xiàn)明顯優(yōu)勢(shì)。值得注意的是,在AI“本行”的計(jì)算機(jī)科學(xué)領(lǐng)域,涉及算法復(fù)雜度分析的題目同樣讓模型折戟,準(zhǔn)確率不足8%。
“深度思考”模型的高昂代價(jià)引發(fā)產(chǎn)業(yè)反思。為提升準(zhǔn)確率,o3-mini等推理模型需生成數(shù)千個(gè)中間推理步驟,導(dǎo)致計(jì)算成本激增5-10倍。以數(shù)學(xué)問(wèn)題為例,Gemini 2.0需處理超8000個(gè)token的推理鏈,但準(zhǔn)確率僅13.4%。這種“暴力計(jì)算”模式暴露AI發(fā)展困境:每提升1%準(zhǔn)確率,需付出指數(shù)級(jí)增長(zhǎng)的計(jì)算資源,形成明顯的收益遞減效應(yīng)。
AI的“虛假自信”現(xiàn)象成為重大安全隱患。所有測(cè)試模型均存在超70%的校準(zhǔn)誤差,即宣稱80%把握的答案實(shí)際正確率不足30%。這種盲目自信源于統(tǒng)計(jì)學(xué)習(xí)機(jī)制——模型通過(guò)模式匹配生成看似合理的回答,卻無(wú)法判斷自身知識(shí)邊界。研究警告,在醫(yī)療、法律等高風(fēng)險(xiǎn)領(lǐng)域,AI的錯(cuò)誤自信可能導(dǎo)致嚴(yán)重決策失誤。
測(cè)試數(shù)據(jù)集的公開(kāi)為全球AI研究提供新基準(zhǔn)。研究團(tuán)隊(duì)保留部分題目作為私有測(cè)試集,防止模型通過(guò)“背題”提升分?jǐn)?shù)。盡管預(yù)測(cè)AI可能在2025年底達(dá)到50%準(zhǔn)確率,但專家強(qiáng)調(diào),這僅代表閉合式學(xué)術(shù)能力,與真正的通用智能(涵蓋創(chuàng)造力、情感理解等)仍有本質(zhì)區(qū)別。這場(chǎng)測(cè)試更像AI發(fā)展路上的“成人禮”,而非終點(diǎn)。
教育領(lǐng)域已開(kāi)始思考變革方向。若AI最終突破專家級(jí)學(xué)術(shù)測(cè)試,傳統(tǒng)知識(shí)傳授模式將面臨挑戰(zhàn)。研究團(tuán)隊(duì)建議,教育應(yīng)更注重培養(yǎng)AI難以替代的能力——?jiǎng)?chuàng)造力、批判思維、跨學(xué)科整合及人際交往。正如測(cè)試揭示的,人類專家在面對(duì)未知時(shí)的認(rèn)知謙遜與深度洞察,仍是AI無(wú)法復(fù)制的核心優(yōu)勢(shì)。