7 月 7 日消息,B站團隊的開源動漫視頻生成模型 AniSora 于 7 月 2 日更新到 AniSora V3 預覽版。
作為 Index-AniSora 項目的一部分,V3 版本在原有基礎上進一步優化了生成質量、動作流暢度和風格多樣性,為動漫、漫畫及 VTuber 內容創作者提供了更強大的工具。
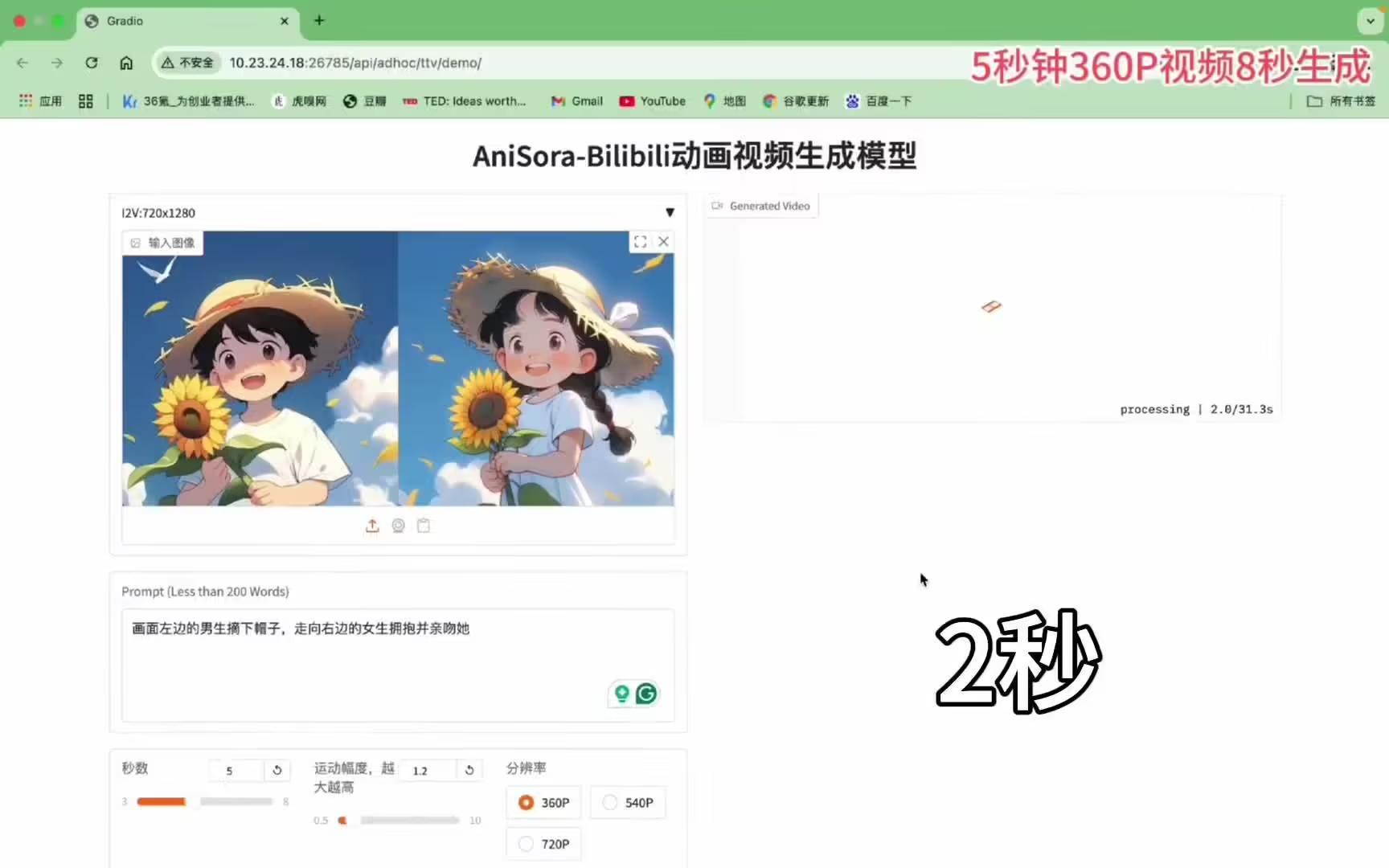
AniSora 支持一鍵生成多種動漫風格的視頻鏡頭,包括番劇片段、國創動畫、漫畫改編、VTuber 內容、動畫 PV、鬼畜(MAD)等。

AniSora V3 基于B站此前開源的 CogVideoX-5B 和 Wan2.1-14B 模型,結合強化學習與人類反饋(RLHF)框架,顯著提升了生成視頻的視覺質量和動作一致性。其支持一鍵生成多種風格的動漫視頻鏡頭,包括番劇片段、國創動畫、漫畫視頻改編、VTuber 內容等。
核心升級包括:
時空掩碼模塊(Spatiotemporal Mask Module)優化:V3 版本增強了時空控制能力,支持更復雜的動畫任務,如精細的角色表情控制、動態鏡頭移動和局部圖像引導生成。例如,提示“五位女孩在鏡頭放大時起舞,左手上舉至頭頂再下放至膝蓋”能生成流暢的舞蹈動畫,鏡頭與角色動作同步自然。
數據集擴展:V3 繼續依托超過 1000 萬高質量動漫視頻片段(從 100 萬原始視頻中提取)進行訓練,新增數據清洗流水線,確保生成內容的風格一致性和細節豐富度。
硬件優化:V3 新增對華為 Ascend910B NPU 的原生支持,完全基于國產芯片訓練,推理速度提升約 20%,生成 4 秒高清視頻僅需 2-3 分鐘。
多任務學習:V3 強化了多任務處理能力,支持從單幀圖像生成視頻、關鍵幀插值到唇部同步等功能,特別適合漫畫改編和 VTuber 內容創作。
在最新基準測試中,AniSora V3 在 VBench 和雙盲主觀測試中,角色一致性和動作流暢度均達到業界頂尖水平(SOTA),尤其在復雜動作 (如違反物理規律的夸張動漫動作) 上表現突出。
V3 還引入了首個針對動漫視頻生成的 RLHF 框架,通過 AnimeReward 和 GAPO 等工具對模型進行微調,確保輸出更符合人類審美和動漫風格需求。社區開發者已開始基于 V3 開發定制化插件,例如增強特定動漫風格(如吉卜力風)的生成效果。
AniSora V3 支持多種動漫風格,包括日本動漫、國產原創動畫、漫畫改編、VTuber 內容及惡搞動畫(鬼畜動畫),覆蓋 90% 的動漫視頻應用場景。具體應用包括:
單圖轉視頻:用戶上傳一張高質量動漫圖像,配合文本提示(如“角色在向前行駛的車中揮手,頭發隨風擺動”),即可生成動態視頻,保持角色細節和風格一致。
漫畫改編:從漫畫幀生成帶唇部同步和動作的動畫,適合快速制作預告片或短篇動畫。
VTuber 與游戲:支持實時生成角色動畫,助力獨立創作者和游戲開發者快速測試角色動作。
高分辨率輸出:生成視頻支持高達 1080p,確保在社交媒體、流媒體平臺上的專業呈現。
AIbase 測試顯示,V3 在生成復雜場景(如多角色交互、動態背景)時,相比 V2 減少了約 15% 的偽影問題,生成時間縮短至平均 2.5 分鐘(注:4 秒視頻)。
相比 OpenAI 的 Sora 或 Kling 等通用視頻生成模型,AniSora V3 專注于動漫領域。與字節跳動的 EX-4D 相比,AniSora V3 更專注于 2D / 2.5D 動漫風格,而非 4D 多視角生成。