阿里巴巴旗下的通義實驗室近期在音頻技術領域邁出了重要一步,正式推出了其首個開源音頻生成模型——ThinkSound。這一創新模型的最大亮點在于,它將思維鏈(CoT)技術首次融入音頻生成過程,意在克服現有視頻轉音頻(V2A)技術在理解和表達視頻動態細節及事件邏輯方面的局限。
據通義語音團隊詳細介紹,傳統的V2A技術往往難以精確捕捉視頻畫面與聲音之間的時空對應關系,導致生成的音頻與視頻中的關鍵事件無法準確同步。而ThinkSound通過引入一種結構化的推理機制,模擬了人類音效師的工作流程:首先,它理解視頻的整體內容和場景語義;接著,聚焦于具體的聲源對象;最后,根據用戶的編輯指令,逐步生成高度逼真且與視頻內容同步的音頻。
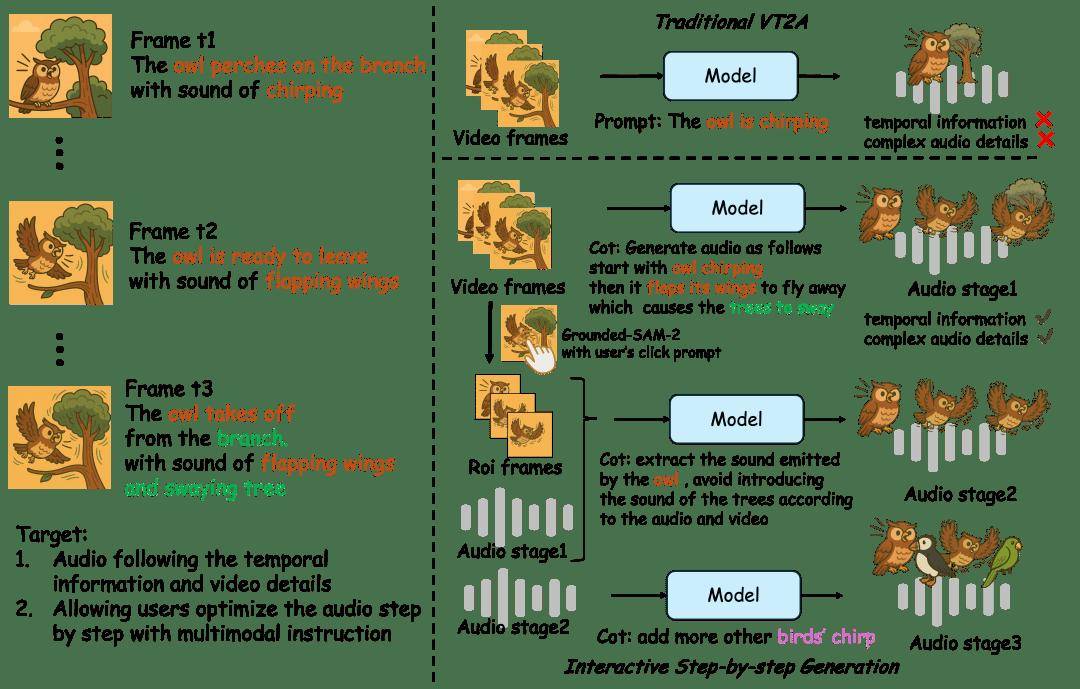
為了訓練這一先進的模型,通義實驗室構建了一個名為AudioCoT的多模態音頻數據集,這是首個支持鏈式推理的數據集。該數據集包含了超過2531小時的高質量樣本,涵蓋了多種場景,并特別設計了面向交互編輯的對象級和指令級數據。ThinkSound模型本身由兩部分組成:一個多模態大語言模型,負責進行“思考”和推理鏈的構建;以及一個統一的音頻生成模型,負責“輸出”最終的聲音。
據悉,ThinkSound在多個權威測試中均展現出了優于現有主流方法的表現。目前,該模型已經面向開發者開源,他們可以在GitHub、Hugging Face和魔搭社區等平臺上獲取相關的代碼和模型。這一開源舉措無疑將促進音頻生成技術的進一步發展和創新,同時也為游戲、虛擬現實(VR)、增強現實(AR)等沉浸式應用場景提供了更多可能性。