近日,中國(guó)開源大模型領(lǐng)域迎來了新的進(jìn)展。在Kimi K2風(fēng)頭正勁之時(shí),Qwen3宣布了最新升級(jí),其235B參數(shù)規(guī)模雖僅為Kimi K2 1T的四分之一,但在基準(zhǔn)測(cè)試中的表現(xiàn)卻超越了后者。
據(jù)悉,Qwen官方此次決定摒棄混合思維模式,轉(zhuǎn)而分別訓(xùn)練Instruct和Thinking模型。新發(fā)布的Qwen3-235B-A22B-2507版本目前僅支持非思考模式,且網(wǎng)頁(yè)版已上線使用,但通義APP尚未更新。
盡管Qwen官方表示這只是“一個(gè)小更新”,但新模型的改進(jìn)之處卻不容小覷。它顯著增強(qiáng)了通用能力,包括指令遵循、邏輯推理、文本理解、數(shù)學(xué)、科學(xué)、編碼和工具使用等方面。同時(shí),多語言長(zhǎng)尾知識(shí)的覆蓋范圍也大幅增加,更符合用戶在主觀和開放式任務(wù)中的偏好,能夠提供更有幫助的響應(yīng)和更高質(zhì)量的文本生成。
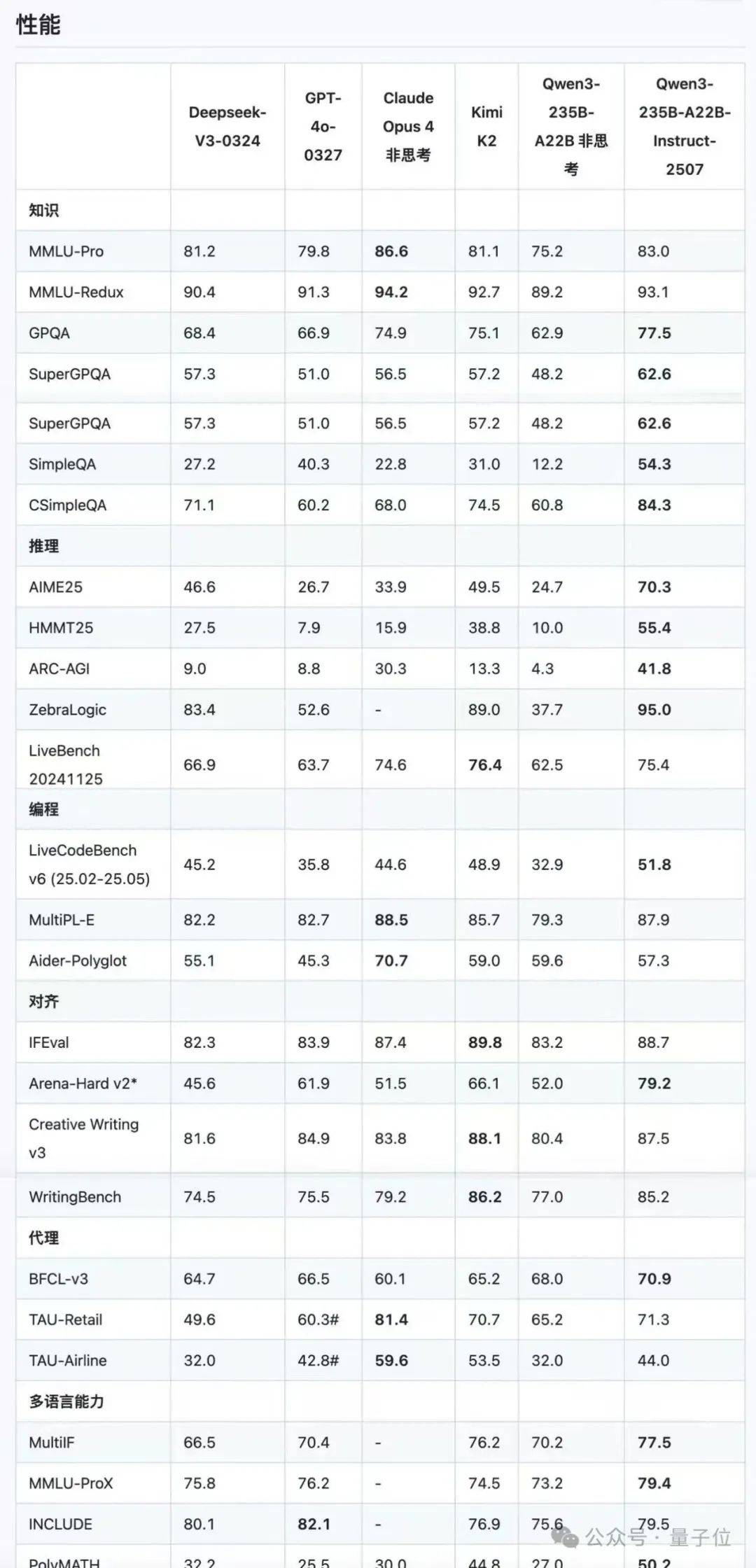
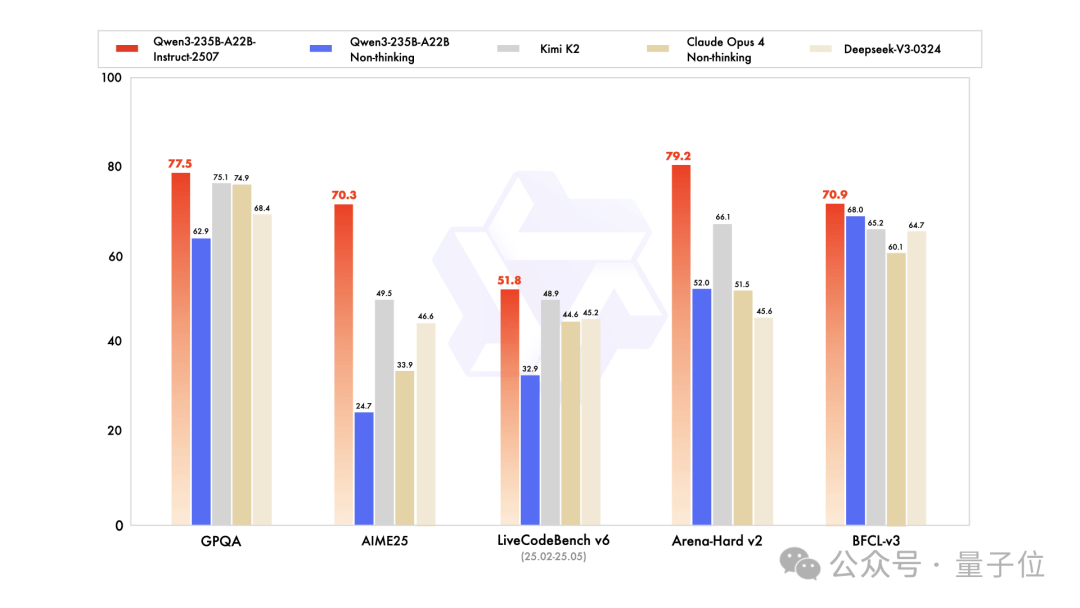
尤其新模型對(duì)256K長(zhǎng)上下文的理解能力得到了顯著增強(qiáng)。在官方發(fā)布的基準(zhǔn)測(cè)試中,相較于上一版本,新模型在AIME25上的準(zhǔn)確率從24.7%飆升至70.3%,顯示出卓越的數(shù)學(xué)推理能力。與Kimi K2和DeepSeek-V3相比,Qwen3新模型的能力也略勝一籌。
為了提高用戶體驗(yàn),Qwen官方還推薦了最佳設(shè)置。新模型的發(fā)布迅速收獲了一眾好評(píng),有網(wǎng)友認(rèn)為Qwen在中等規(guī)模的語言模型中已經(jīng)處于領(lǐng)先地位,甚至開啟了新的架構(gòu)范式。
就在Qwen3新模型發(fā)布的前幾天,NVIDIA也宣稱發(fā)布了新的SOTA開源模型OpenReasoning-Nemotron。然而,該模型實(shí)際上是基于Qwen-2.5在Deepseek R1數(shù)據(jù)上微調(diào)而來的。隨著Qwen3的更新和大招的預(yù)告,以及Llama轉(zhuǎn)向閉源的消息傳出,開源基礎(chǔ)大模型的競(jìng)爭(zhēng)正逐漸進(jìn)入中國(guó)時(shí)間。
此前,DeepSeek曾占據(jù)王座,隨后被Kimi K2取代。然而,Kimi K2坐穩(wěn)沒幾天,就迎來了Qwen的挑戰(zhàn)。如今,中國(guó)開源大模型領(lǐng)域的競(jìng)爭(zhēng)愈發(fā)激烈,各大模型紛紛升級(jí)迭代,力求在市場(chǎng)中占據(jù)一席之地。
Qwen3新版本的體驗(yàn)鏈接已開放,感興趣的用戶可前往https://chat.qwen.ai/進(jìn)行體驗(yàn)。