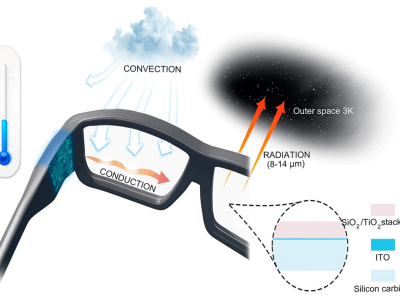
阿里巴巴通義實驗室近期宣布了一項重大開源成果——音頻生成模型ThinkSound。該模型標志著首次將CoT(Chain-of-Thought,思維鏈)技術應用于音頻生成領域,使得人工智能能夠模擬專業音效師的思考過程,精準捕捉視覺細節,并生成與視頻畫面高度同步的高保真音頻。
ThinkSound的代碼與模型已在多個平臺,包括Github、HuggingFace以及魔搭社區上公開,開發者可以免費獲取并體驗這一創新技術。這一舉措無疑將極大地推動音頻生成技術的普及與發展。
視頻生成音頻(V2A)技術一直是多媒體編輯和視頻內容創作領域的關鍵技術之一。然而,現有技術仍面臨諸多挑戰,尤其是難以準確捕捉視頻中的動態細節和時序關系,導致生成的音頻往往缺乏與關鍵視覺事件的精確對應,難以滿足專業創意場景中對時序和語義連貫性的高要求。
為了突破這一技術瓶頸,通義實驗室創新性地將思維鏈推理引入多模態大模型,使模型能夠模仿人類音效師的多階段創作流程。通過對視覺事件與相應聲音之間深度關聯的精準建模,模型能夠先分析視覺動態、再推斷聲學屬性,并按照時間順序合成與環境相符的音效。通義實驗室還構建了首個帶思維鏈標注的音頻數據集AudioCoT,該數據集融合了超過2500小時的多源異構數據,為模型的訓練提供了強有力的支持。
在開源的VGGSound測試集上,ThinkSound展現出了卓越的性能。其核心指標相比現有主流方法如MMAudio、V2A-Mappe、V-AURA等,均實現了15%以上的提升。特別是在openl3空間中的Fréchet距離(FD)指標上,ThinkSound的表現接近真實音頻分布,相似度提高了20%以上。同時,在代表模型對聲音事件類別和特征判別精準度的KLPaSST和KLPaNNs兩項指標上,ThinkSound也均取得了同類模型中的最佳成績。
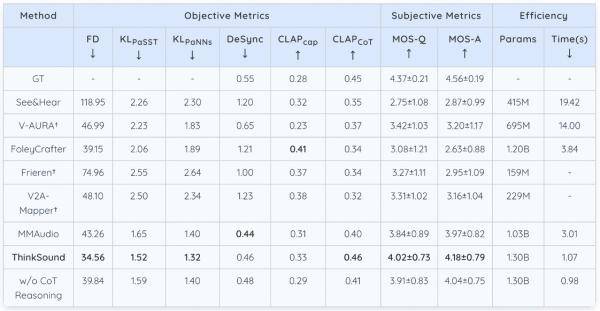
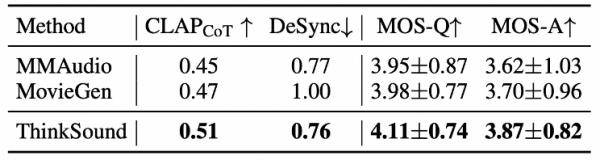
不僅如此,在MovieGen Audio Bench測試集上,ThinkSound的表現也大幅領先meta推出的音頻生成模型Movie Gen Audio。這一成績進一步證明了ThinkSound在影視音效、音頻后期、游戲與虛擬現實音效生成等領域的廣泛應用潛力。
通義實驗室在音頻生成領域已有多項成果。除了ThinkSound外,還推出了語音生成大模型Cosyvoice和端到端音頻多模態大模型MinMo等,這些模型共同構成了覆蓋語音合成、音頻生成、音頻理解等場景的全面解決方案。