華為近日宣布了一項重大舉措,針對超大規模MoE(混合專家)模型的推理問題,開源了其名為Omni-Infer的新項目。這一行動無疑為眾多企業用戶和開發者帶來了福音。
Omni-Infer項目包含了推理框架與推理加速套件兩大核心部分。推理框架方面,Omni-Infer與業內的主流開源大模型推理框架如vLLM等實現了完美兼容,這類似于不同品牌的組件能夠無縫集成在同一系統中。同時,Omni-Infer的功能還在不斷拓展,旨在為昇騰硬件平臺上的大模型推理提供更強大的支持。
值得注意的是,Omni-Infer與vLLM、SGLang等主流框架是解耦的,用戶可以獨立安裝,這大大降低了軟件版本維護的成本。用戶只需關注vLLM等框架的主版本,即可享受Omni-Infer帶來的便利。
而Omni-Infer的推理加速套件則更像是一位企業級的“智能調度員”。它擁有智能調度系統,能夠合理安排任務,支持大規模分布式部署,確保任務處理的低延遲和高效率。同時,它還是一個精準的“負載平衡器”,針對不同長度的任務序列,在預填充和解碼階段都做了優化,以實現最大吞吐量和低延遲。
對于MoE模型來說,Omni-Infer更是其“專屬搭檔”。它支持多種配置,如EP144/EP288等,讓混合專家模型能夠高效協作。Omni-Infer還具備分層非均勻冗余和近實時動態專家放置功能,智能地分配資源,確保資源的充分利用。
為了讓AI推理更快更穩,Omni-Infer還專門為LLM、MLLM和MoE等模型優化了注意力機制。這一優化讓模型在處理信息時更加聚焦和高效,提升了性能和可擴展性。
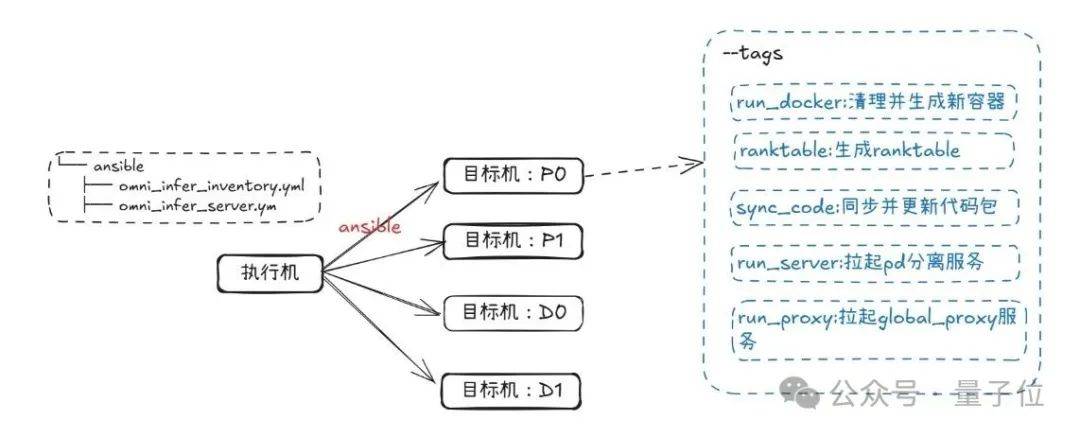
體驗Omni-Infer也并不復雜。首先,它目前僅支持CloudMatrix384推理卡和特定版本的Linux操作系統。安裝方面,用戶可以通過Docker鏡像方式進行安裝,只需運行一條命令即可獲取預先集成所需的CANN及Torch-NPU依賴包,同時內置可直接運行的Omni-Infer與vLLM工具包。
以PD分離自動化部署為例,用戶只需按照文檔教程,通過少量代碼和步驟即可完成安裝和部署。整個過程簡單快捷,讓AI推理變得更加高效。
除了技術上的開源,華為還為Omni-Infer建立了專業的開源社區。社區倉庫中包含了社區治理、會議、活動、生態合作、代碼規范、設計文檔等全面信息,讓開發者能夠深入參與到社區發展中。同時,Omni-Infer社區采用了開放的治理機制,提供公正透明的討論與決策環境。
Omni-Infer社區采取了“主動適配”的生態合作模式,積極擁抱國內正在成長的人工智能開源項目,實現生態的多方共贏。作為與業界主流開源基金會保持緊密合作關系的社區團隊,Omni-infer的首個活動就將參與OpenInfra基金會在蘇州的Meetup,為開發者提供了交流與學習的機會。
對于感興趣的開發者和小伙伴來說,Omni-Infer的技術報告、可分析代碼包以及更多相關信息已經全面開放,大家可以自行獲取并參與到這一開源項目中來。