隨著人工智能技術的飛速發展,一類全新的自主智能體正逐漸嶄露頭角,它們的核心驅動力是近年來取得突破性進展的大型語言模型(LLMs)。這些智能體不僅能夠感知環境、進行復雜推理,還能在無需人類持續監督的情況下,通過調用各種工具執行多步驟任務,形成閉環反饋機制。這一轉變標志著AI技術從靜態預測模型向主動、具身智能體的重大跨越。
與傳統AI系統相比,基于LLMs的智能體擁有更為廣闊的行動空間和更強的適應性。它們能夠閱讀動態上下文、即興學會新工具,并在運行時調整計劃,追求既定目標。這種靈活性使得LLMs智能體在軟件編程、網頁自動化、個人助理乃至機器人控制等領域展現出巨大潛力,被視為通用人工智能發展的重要里程碑。
然而,隨著智能體自主性的增強,一系列前所未有的安全風險也隨之浮現。由于智能體能夠執行具有真實后果的行為,如執行代碼、修改數據庫或調用API,因此系統故障和對抗性攻擊的風險被大幅放大。這些風險源于智能體的核心特性:多步推理、動態工具使用和面向環境的適應性,這些特性擴展了攻擊面,使得智能體在多個系統層級上均可能遭受攻擊。
為了應對這些挑戰,研究者們近年來提出了多種防御策略,包括輸入凈化、記憶生命周期控制、受限決策制定、結構化工具調用以及內省式反思機制等。然而,這些策略大多孤立實施,缺乏對跨模塊、跨時間維度涌現性威脅的系統性響應能力。因此,迫切需要一種更為統一、前瞻性的安全保障框架。

在此背景下,反思性風險感知智能體架構(R2A2)應運而生。這一統一的認知框架基于受限馬爾可夫決策過程(CMDPs),融合了風險感知世界建模、元策略適應以及獎勵–風險聯合優化機制。R2A2旨在智能體的決策循環中實現系統化、前瞻性的安全保障,從而有效應對自主性增強帶來的安全挑戰。
R2A2架構的提出,不僅為智能體的安全性設計提供了理論藍圖,也為下一代AI智能體的發展指明了方向。通過將安全性作為核心設計原則,R2A2有望在確保智能體可靠追求有益目標、配合人類監督的同時,降低目標錯配帶來的風險。這對于推動人工智能技術的健康、可持續發展具有重要意義。
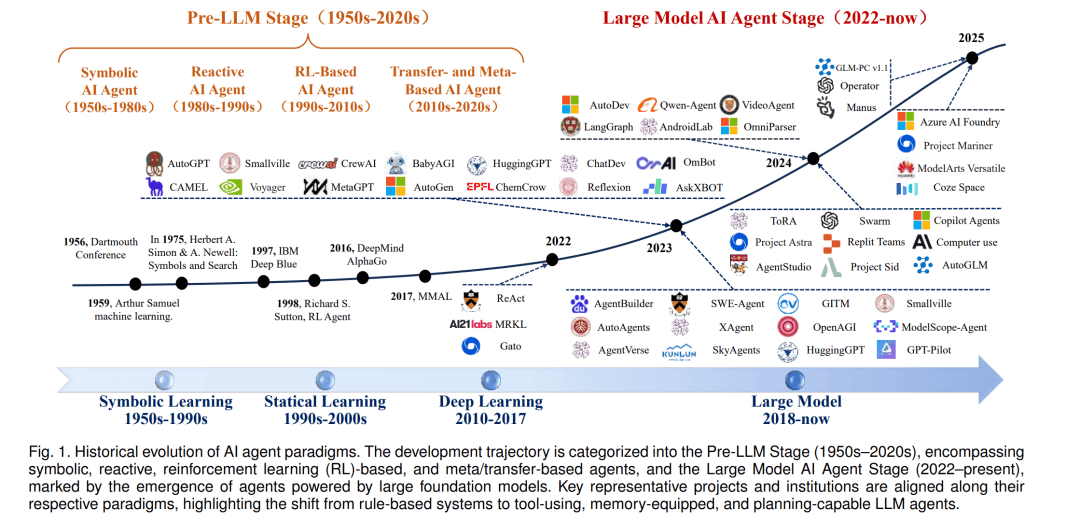
值得注意的是,盡管基于LLMs的智能體帶來了前所未有的變革潛力,但其安全性問題同樣不容忽視。未來,隨著技術的不斷進步和應用場景的不斷拓展,如何進一步完善智能體的安全保障機制,將成為AI領域亟待解決的關鍵問題之一。同時,加強跨學科合作、推動技術創新與倫理規范的協同發展,也將是確保人工智能技術健康發展的重要保障。