7 月 5 日消息,AI 聊天機器人平臺 Character.AI 發布研究論文和視頻演示,展示了名為 TalkingMachines 的自回歸擴散模型,讓 AI 角色互動更加逼真。
該模型尚未部署在 Character.AI 平臺上,根據研究論文和視頻演示,用戶只需要輸入一張圖片和聲音信號,該模型就能實現類似 FaceTime 的通話視覺互動。
該模型基于 Diffusion Transformer(DiT)技術,本質上是一種能夠從隨機噪聲中創建詳細圖像的“藝術家”,并不斷優化圖像直至完美。Character.AI 所做的就是讓這一過程變得極其迅速,達到實時效果。

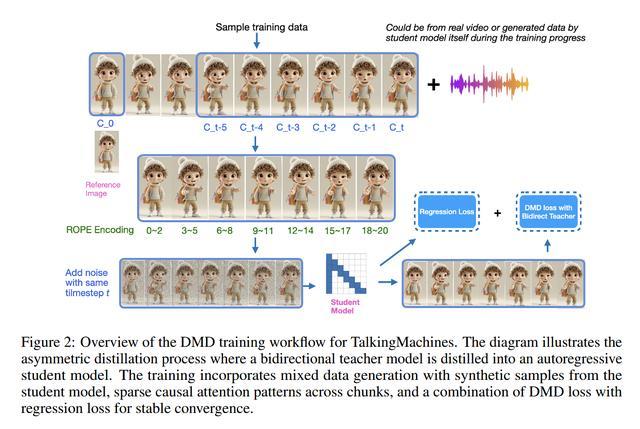
TalkingMachines 模型采用了流匹配擴散(Flow-Matched Diffusion)、音頻驅動的交叉注意力(Audio-Driven Cross Attention)、稀疏因果注意力(Sparse Causal Attention)和不對稱蒸餾(Asymmetric Distillation)等多種關鍵技術。
其中流匹配擴散技術通過訓練大量動作,包括細微的面部表情和更夸張的手勢,確保 AI 角色動作更加自然。音頻驅動的交叉注意力技術則讓 AI 不僅能聽到單詞,還能理解音頻中的節奏、停頓和語調,并將其轉化為精確的口型、點頭和眨眼。

稀疏因果注意力技術讓 Character.AI 能夠以更高效的方式處理視頻幀,而不對稱蒸餾技術則讓視頻能夠實時生成,營造出類似 FaceTime 通話的效果。

Character.AI 強調,這一研究突破不僅僅是關于面部動畫的,它是朝向實時互動的音頻視覺 AI 角色邁出的一步。該模型支真實感人類、動漫和 3D 虛擬形象等多種風格。