7 月 5 日消息,蘋果公司悄然在 Hugging Face 上發布了一款名為 DiffuCode-7B-cpGRPO 的開源 AI 模型,該模型在生成代碼方面具有創新特性,能夠不按順序生成代碼,且性能媲美頂級開源編碼模型。
注:傳統大語言模型(LLM)生成代碼的方式,如同大多數人類閱讀文本的方式,采用從左到右、從上到下順序。
這主要是因為這些 LLM 采用自回歸(Autoregression)方式工作,意味著當用戶向它們提問后,它們會處理整個問題,預測答案的第一個 token,然后帶著這個 token 重新處理整個問題,預測第二個 token,以此類推。
LLM 還有一個名為“溫度”(Temperature)的設置,用于控制輸出的隨機性。在預測下一個 token 后,模型會為所有可能的選項分配概率。較低的溫度意味著更有可能選擇最可能的 token,而較高的溫度則給予模型更多的自由,選擇不太可能的 token。
而另一種選擇就是擴散(Diffusion)模型,這種模型通常用于圖像模型。簡而言之,模型從一個模糊、噪聲的圖像開始,迭代去除噪聲,同時考慮到用戶的需求,逐漸將其引導至更接近用戶請求的圖像。

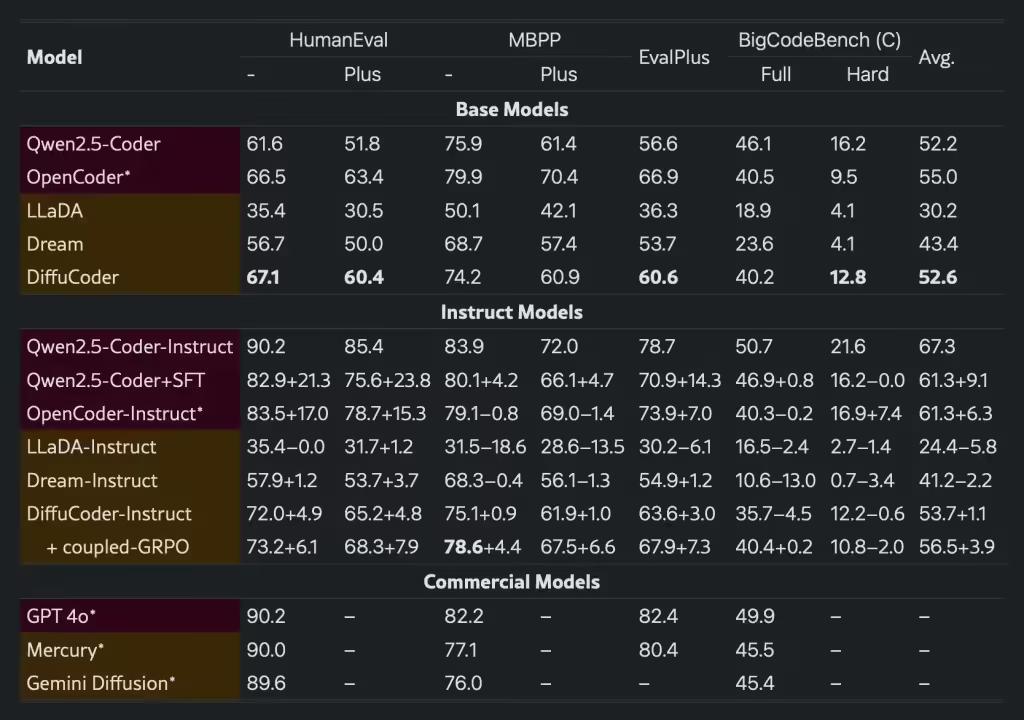
蘋果公司發布的模型名為 DiffuCode-7B-cpGRPO,它基于上月發表、名為《DiffuCoder: Understanding and Improving Masked Diffusion Models for Code Generation》的論文。
論文描述了一個采用擴散優先策略的代碼生成模型,但有一個特別之處:當采樣溫度從默認的 0.2 增加到 1.2 后,DiffuCoder 在生成 token 的順序上變得更加靈活,從而擺脫了嚴格的從左到右的約束。
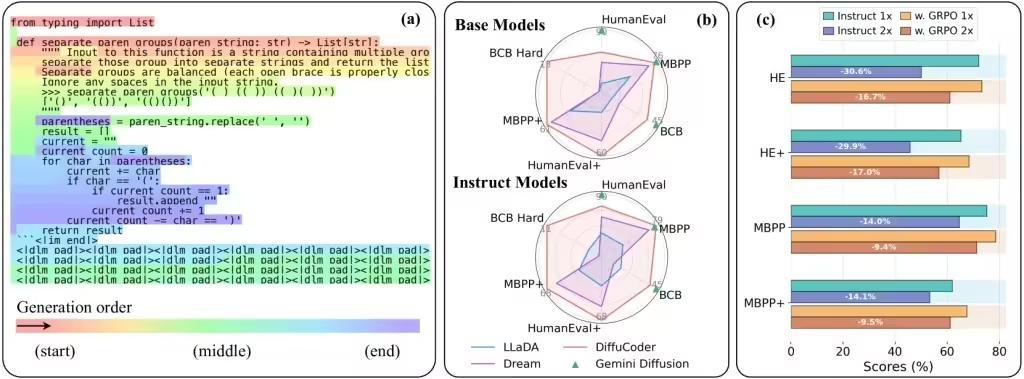
更為有趣的是,蘋果的這款模型建立在阿里的開源 Qwen2.5-7B 模型上,將這個模型按照 DiffuCoder 論文中的描述,改造成了一個基于擴散的 decoder,然后調整它以更好地遵循指示。完成這些后,他們又用超過 20000 個精心挑選的編碼示例訓練了它的另一個版本。

在主流編程跑分中,DiffuCode-7B-cpGRPO 保持了在生成代碼時不嚴格依賴從左到右的生成方式情況下,相比較主流基于擴散的編程模型,測試得分提高了 4.4%。