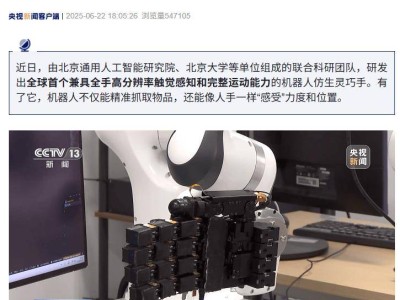
在科技界掀起波瀾的并非總是那些財大氣粗的行業(yè)巨頭,DeepSeek公司以其R1模型的發(fā)布,向世界展示了低成本高效能的AI開發(fā)新路徑。這一創(chuàng)新不僅震撼了整個科技領(lǐng)域,還迫使行業(yè)內(nèi)的領(lǐng)頭羊重新審視并調(diào)整其AI研發(fā)策略。
DeepSeek的成功并非依賴于突破性的新功能,而是其利用有限資源創(chuàng)造出了與科技巨頭比肩的成果。面對美國對高端AI芯片的出口限制,DeepSeek沒有被困境束縛,而是選擇了一條優(yōu)化現(xiàn)有資源的道路。當其他公司競相追逐更強大的硬件和更大的模型時,DeepSeek卻以出色的執(zhí)行力,將已知的理念轉(zhuǎn)化為現(xiàn)實,展現(xiàn)了在限制條件下創(chuàng)新的力量。
值得注意的是,DeepSeek在芯片方面的劣勢并非不可逾越的障礙。美國的出口管制主要限制了計算能力,而對內(nèi)存和網(wǎng)絡(luò)的影響相對較小,而這兩者是AI發(fā)展的關(guān)鍵要素。因此,DeepSeek所使用的芯片在內(nèi)存和網(wǎng)絡(luò)功能方面表現(xiàn)出色,能夠在多個單元之間并行執(zhí)行操作,這對于高效運行大型模型至關(guān)重要。中國在人工智能基礎(chǔ)設(shè)施垂直堆棧上的大力推動,也為DeepSeek的創(chuàng)新提供了有力支持。
DeepSeek在訓(xùn)練數(shù)據(jù)方法上也獨樹一幟。它并非僅僅依賴于從網(wǎng)絡(luò)上抓取的內(nèi)容,而是大量利用了合成數(shù)據(jù)和其他專有模型的輸出。這種方法雖然可能引發(fā)西方企業(yè)客戶對數(shù)據(jù)隱私和治理的擔憂,但卻彰顯了DeepSeek注重結(jié)果、不拘一格的務(wù)實態(tài)度。DeepSeek等基于Transformer且采用混合專家(MoE)架構(gòu)的模型,在整合合成數(shù)據(jù)時表現(xiàn)出更強的穩(wěn)健性,而傳統(tǒng)密集架構(gòu)的模型則可能因過度使用合成數(shù)據(jù)而導(dǎo)致性能下降甚至崩潰。DeepSeek的工程團隊在模型架構(gòu)設(shè)計時,就充分考慮了合成數(shù)據(jù)的集成,從而在不犧牲性能的前提下,充分利用了合成數(shù)據(jù)的成本效益。
DeepSeek的崛起已經(jīng)引發(fā)了行業(yè)領(lǐng)導(dǎo)者的戰(zhàn)略調(diào)整。OpenAI首席執(zhí)行官Sam Altman近期宣布計劃發(fā)布公司自2019年以來的首個“開放權(quán)重”語言模型,這一變化顯然受到了DeepSeek和Llama等模型成功的影響。DeepSeek推出僅一個月后,Altman就承認OpenAI在開源AI方面“站錯了歷史的一邊”。面對高達每年70億至80億美元的運營成本,DeepSeek等高效替代方案帶來的經(jīng)濟壓力已經(jīng)不容忽視。盡管OpenAI進行了高達400億美元的融資,公司估值達到3000億美元,但其方法比DeepSeek耗費更多資源的根本問題依然存在。
DeepSeek還在推動AI系統(tǒng)自主評估和改進方面取得了進展。隨著預(yù)訓(xùn)練模型對公共數(shù)據(jù)的利用接近飽和,數(shù)據(jù)稀缺正在成為制約預(yù)訓(xùn)練進一步改進的瓶頸。為解決這一問題,DeepSeek與清華大學(xué)合作,實現(xiàn)了“自我原則性評論調(diào)優(yōu)”(SPCT),即AI開發(fā)自己的內(nèi)容評判規(guī)則,并利用這些規(guī)則提供詳細評論,包含內(nèi)置的“評委”實時評估AI的答案。這一進展標志著AI系統(tǒng)開始利用推理時間來改進結(jié)果,而非僅僅依賴于增大模型規(guī)模。然而,這種方法也伴隨著風險:如果AI制定了自己的評判標準,可能會偏離人類價值觀、倫理道德,甚至強化錯誤的假設(shè)或幻覺,從而引發(fā)對AI自主判斷的擔憂。
DeepSeek的異軍突起,不僅展示了在限制條件下創(chuàng)新的可能性,還預(yù)示了人工智能行業(yè)將朝著并行創(chuàng)新軌道發(fā)展的趨勢。各大公司在繼續(xù)構(gòu)建更強大的計算集群的同時,也將更加關(guān)注通過軟件工程和模型架構(gòu)改進來提升效率。微軟已經(jīng)停止了全球多個地區(qū)的數(shù)據(jù)中心建設(shè),轉(zhuǎn)向更加分布式、高效的基礎(chǔ)設(shè)施建設(shè),并計劃重新分配資源以應(yīng)對DeepSeek帶來的效率挑戰(zhàn)。meta也發(fā)布了首次采用MoE架構(gòu)的Llama4模型系列,并將其與DeepSeek模型進行基準測試,這標志著中國AI模型已經(jīng)成為硅谷公司值得參考的基準。