在人工智能與生物科學的交叉領域,一場革命性的變革正在悄然發生。大模型,這一通過自監督或半監督學習,在海量未標注數據上訓練的深度神經網絡模型,正展現出前所未有的通用性,不僅在自然語言處理、計算機視覺等領域大放異彩,更在合成生物學研究中開辟了新的道路。
合成生物學,這一旨在理解并重新設計生物系統的科學,如今借助大模型的強大能力,解決了許多傳統方法難以攻克的難題。以蛋白質研究為例,科學家們利用大模型成功預測了蛋白質的三維結構,這一突破得益于過去數十年對蛋白質結構的深入研究,以及將這些研究成果匯集成大型數據庫的努力。如今,這些模型正以前所未有的方式理解生命分子,推動合成生物學進入一個全新的階段。
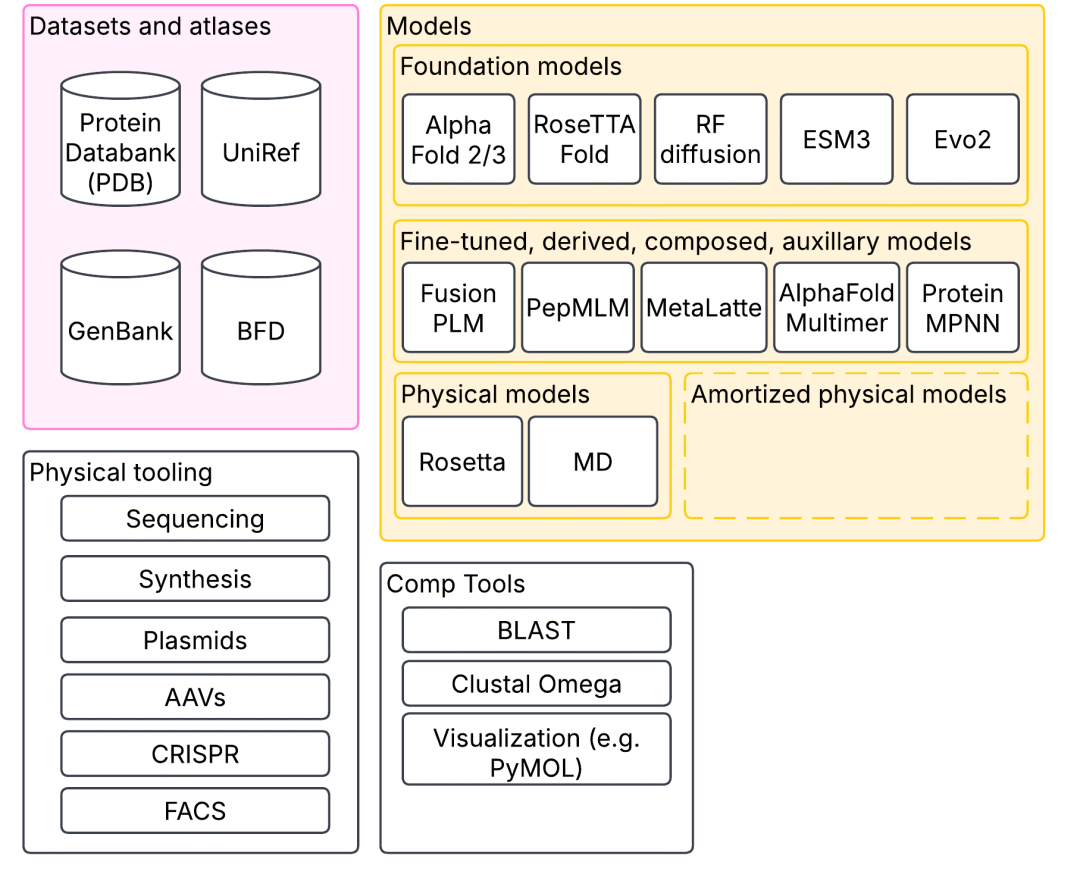
在合成生物學領域,大模型的應用不僅限于蛋白質結構預測。科學家們還利用這些模型模擬了多個蛋白質之間的相互作用,根據功能需求“定制”蛋白質,甚至實現了從結構反推最有可能的氨基酸序列。這些技術進步依賴于長期積累的生態系統支持,包括大量的開源工具、數據庫以及物理建模工具等。
然而,在神經科學領域,盡管對蛋白質的需求極高,從測量神經活動到精確干預神經功能,幾乎每一個關鍵工具都依賴于蛋白質設計,但類似的進展尚未實現。這引發了人們的思考:合成生物學中的經驗是否可以被應用到神經科學的領域?大模型是否能夠幫助神經科學突破過往的界限?
要回答這個問題,我們首先需要審視神經科學數據的現狀。盡管存在一些主流的數據平臺,提供了高質量的大腦活動數據,但這些數據能否構成一個真正的“腦圖譜”仍是個問題。目前,我們仍很難同時獲得具有高空間覆蓋、高空間分辨率以及高任務多樣性的完整數據集。這限制了神經科學大模型的發展。
神經系統的可操作性也是一大挑戰。與可以隨意合成的蛋白質不同,當前神經系統的可操作性遠低于蛋白質合成技術。盡管有一些新的策略,如生物混合器件,將神經元培養在微電極與微型LED上,主動與設備形成交互界面,并逐步生長入腦組織,但這些技術仍處于初級階段。

盡管如此,神經科學領域仍有一些案例展現了閉環優化可能性的雛形。例如,視覺神經元刺激中的“Inception loop”實驗,能夠尋找激活特定視覺神經元的最強刺激;全息光遺傳學干預實驗也展示了對神經活動的主動微調。這些實驗揭示了大模型在閉環控制中的潛力。
面對這些挑戰,神經科學領域需要采取新的策略。一方面,我們需要開展大規模、非假設驅動的神經科學研究,聚焦于工具與數據本身的建設。這種研究可能需要以“聚焦型研究組織”或跨機構協同項目的形式展開。另一方面,我們需要構建一個更加完善的生態系統,包括數據平臺、開源工具、物理建模工具等,以支持大模型在神經科學領域的應用。

在這一過程中,大模型將發揮關鍵作用。它們能夠利用已有和未來的大規模神經數據,學習有效的神經表征,做出預測,并在閉環系統中進行優化。借助深度學習模型的可微特性,我們可以實現自動調整與反饋,從而加速神經科學的研究進程。
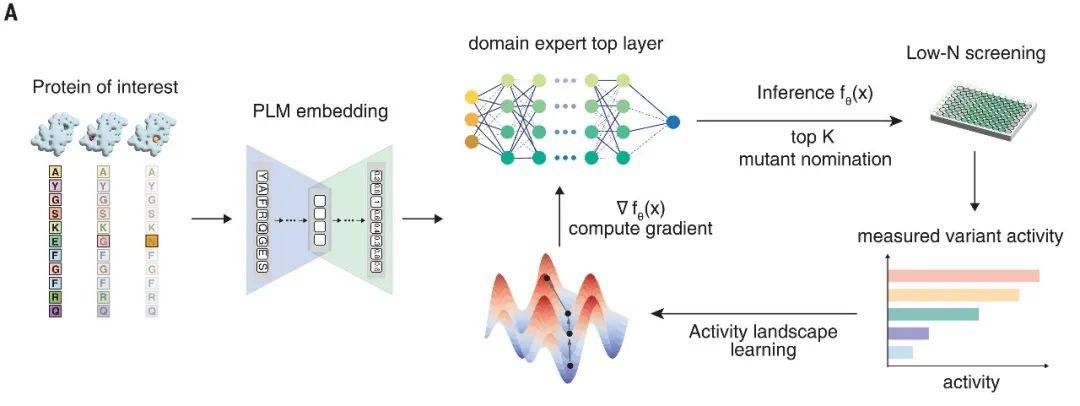
可以預見的是,隨著技術的不斷進步和數據的不斷積累,神經科學領域將迎來更多的突破。這些突破不僅將推動我們對大腦的理解更加深入,還將為神經類疾病的治療提供新的方法和手段。讓我們共同期待這一天的到來。