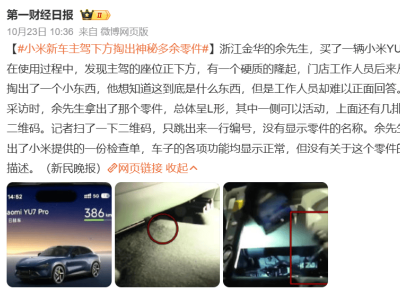
隨著生成式AI技術(shù)的持續(xù)突破,OpenAI在多媒體內(nèi)容生成領(lǐng)域再啟新布局。繼推出現(xiàn)象級產(chǎn)品ChatGPT和AI視頻生成工具Sora后,該公司正秘密研發(fā)一款能夠自動生成音樂的AI模型,試圖在音頻內(nèi)容創(chuàng)作領(lǐng)域開辟新賽道。
據(jù)知情人士透露,該項目已進(jìn)入深度開發(fā)階段。OpenAI團(tuán)隊與全球頂尖音樂學(xué)府茱莉亞音樂學(xué)院展開合作,招募音樂專業(yè)學(xué)生參與核心數(shù)據(jù)標(biāo)注工作。研究人員通過解析大量經(jīng)典樂譜的結(jié)構(gòu)特征,為模型構(gòu)建了包含旋律、節(jié)奏、和聲等要素的精細(xì)化訓(xùn)練庫,確保生成內(nèi)容符合音樂理論規(guī)范。
該技術(shù)最直觀的應(yīng)用場景在于短視頻創(chuàng)作領(lǐng)域。當(dāng)用戶使用Sora生成一段舞蹈視頻后,系統(tǒng)可自動匹配風(fēng)格契合的背景音樂,實現(xiàn)畫面與音效的同步生成。更值得關(guān)注的是,這項功能將與OpenAI正在測試的AI社交平臺形成聯(lián)動,用戶無需切換多個工具即可完成從創(chuàng)意構(gòu)思到成品輸出的全流程創(chuàng)作。
行業(yè)分析師指出,音樂模型的推出將顯著強(qiáng)化OpenAI的生態(tài)競爭力。目前該公司已積累超8億活躍用戶,新增的音頻生成能力不僅能滿足內(nèi)容創(chuàng)作者對多元化素材的需求,更可通過降低專業(yè)門檻吸引更多普通用戶。這種"文字-圖像-視頻-音頻"的全模態(tài)覆蓋戰(zhàn)略,正在重塑數(shù)字內(nèi)容生產(chǎn)的行業(yè)標(biāo)準(zhǔn)。