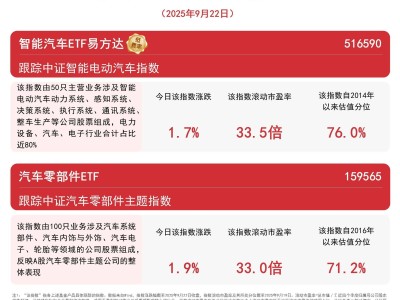
復旦大學研究團隊近期在人工智能訓練領(lǐng)域取得重大突破,開發(fā)出一套名為AgentGym-RL的創(chuàng)新訓練框架。該框架通過模擬人類漸進式學習過程,成功讓僅含70億參數(shù)的小型AI模型在復雜任務中展現(xiàn)出超越千億參數(shù)商業(yè)模型的性能。這項成果已發(fā)表在arXiv平臺,開源代碼和數(shù)據(jù)集同步在GitHub公開。
傳統(tǒng)AI訓練存在顯著局限:多數(shù)系統(tǒng)只能處理單次交互的簡單任務,面對需要多步驟規(guī)劃的復雜場景時表現(xiàn)欠佳。研究團隊形象地比喻,現(xiàn)有AI就像只會背書的學生,缺乏真正的理解和創(chuàng)新能力。在需要持續(xù)互動的任務中,這些系統(tǒng)往往因訓練不穩(wěn)定而崩潰,如同初學者同時學習駕駛和導航般手忙腳亂。
AgentGym-RL框架創(chuàng)造性地設計了五大訓練環(huán)境,構(gòu)建起AI的"虛擬游樂園"。網(wǎng)頁導航環(huán)境模擬真實網(wǎng)站交互,要求AI完成購物、論壇管理等任務;深度搜索環(huán)境訓練信息檢索能力,需整合多個信息源得出結(jié)論;數(shù)字游戲環(huán)境采用文本版Minecraft,考驗策略規(guī)劃和資源管理;具身任務環(huán)境通過虛擬空間導航,測試空間推理能力;科學任務環(huán)境則專注實驗設計和數(shù)據(jù)分析。
研究團隊開發(fā)的ScalingInter-RL訓練方法堪稱框架核心。該方法采用漸進式策略,初期限制AI與環(huán)境的交互次數(shù),使其專注掌握基礎技能,如同教練先讓學員在空曠場地熟悉駕駛。隨著訓練深入,逐步增加交互復雜度,鼓勵探索更高級策略。這種"先易后難"的模式有效解決了傳統(tǒng)強化學習中的探索-利用平衡難題。
實驗數(shù)據(jù)顯示,經(jīng)過AgentGym-RL訓練的70億參數(shù)模型性能提升達33.65個百分點。在網(wǎng)頁導航任務中,該模型準確率達26%,超越GPT-4o的16%和Gemini-2.5-Pro的28%。深度搜索任務表現(xiàn)更為突出,取得38.25分的整體得分,接近頂級開源模型DeepSeek-R1-0528的40.25分。在數(shù)字游戲最高難度級別,該模型是少數(shù)獲得非零分數(shù)的系統(tǒng)之一。
研究團隊發(fā)現(xiàn),增加測試時的計算資源能顯著提升模型表現(xiàn)。當交互回合數(shù)從2次增加到30次時,模型準確率穩(wěn)步上升;并行采樣次數(shù)從1次增至64次,成功率提升最高達7.05個百分點。這表明,對于AI智能體而言,戰(zhàn)略性地投入更多計算資源進行推理,比單純增加模型參數(shù)更有效。
算法比較實驗揭示了訓練方法的重要性。GRPO算法在多個任務中表現(xiàn)優(yōu)于REINFORCE++,使用GRPO訓練的30億參數(shù)模型性能甚至超過使用REINFORCE++訓練的70億參數(shù)模型。研究還發(fā)現(xiàn),訓練初期嚴格限制交互次數(shù)能確保穩(wěn)定性,后期逐步放開則有助于學習復雜策略,這種動態(tài)調(diào)整策略取得了最佳效果。
案例分析生動展示了訓練成果。在網(wǎng)頁導航任務中,經(jīng)過強化學習的模型遇到"頁面未找到"錯誤時,會主動回退到主頁使用搜索功能,而基礎模型則陷入無效點擊循環(huán)。具身導航任務中,訓練后的模型能系統(tǒng)性探索環(huán)境,遇到阻礙時選擇替代路徑,基礎模型則常在已探索區(qū)域徘徊。
環(huán)境結(jié)構(gòu)對學習效果的影響研究帶來重要啟示。在規(guī)則明確的模擬環(huán)境中,如數(shù)字游戲和科學實驗,強化學習效果最為顯著,模型得分提升幅度接近50個百分點。而在更開放的網(wǎng)頁導航和深度搜索環(huán)境中,提升幅度相對溫和。這表明訓練初期應優(yōu)先選擇結(jié)構(gòu)化環(huán)境,逐步引入復雜場景。
這項研究不僅在技術(shù)上取得突破,更體現(xiàn)了方法創(chuàng)新的重要性。通過漸進式訓練和多樣化環(huán)境設計,小規(guī)模模型也能獲得強大能力。開源框架的發(fā)布為全球研究者提供了研究基礎,促進了AI智能體技術(shù)的普及。研究顯示,中國在AI基礎研究領(lǐng)域的創(chuàng)新能力正不斷提升,為國際AI社區(qū)貢獻了新的智慧。
對技術(shù)細節(jié)感興趣的讀者可訪問項目GitHub頁面獲取完整代碼和數(shù)據(jù)集,或查閱arXiv平臺上的完整論文(編號:arXiv:2509.08755v1)。這項研究將推動AI從簡單問答向真正理解復雜任務、制定長期計劃的智能伙伴發(fā)展,在網(wǎng)頁操作、信息搜索、科學研究等領(lǐng)域展現(xiàn)廣闊應用前景。