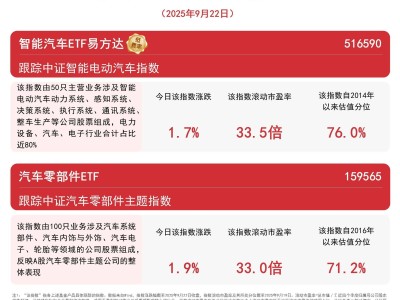
當人類走進便利店尋找特定飲料時,即便貨架上商品琳瑯滿目,我們也能迅速鎖定目標。這種看似簡單的視覺定位能力,對人工智能而言卻是一道難題。中國科學院計算技術研究所的研究團隊針對這一挑戰,提出了一種名為CARVE的創新解決方案,有效提升了AI在復雜場景中的視覺推理能力。
研究團隊發現,現有AI視覺語言模型在處理復雜圖像時,注意力容易分散。就像人在嘈雜環境中難以集中精神一樣,AI面對包含大量視覺元素的圖片時,往往會被無關信息干擾,導致任務執行效率下降。這種注意力分散的程度與圖像的視覺復雜度密切相關,研究團隊通過量化分析證實,圖像的紋理復雜度和顏色復雜度越高,AI的注意力就越難以集中。
CARVE方法的核心在于構建了一種對比注意力機制。該方法不需要對現有AI模型進行重新訓練,而是通過設計兩種不同的觀察指令來引導模型。首先讓AI以通用指令(如"描述圖片")觀察圖像,此時模型的注意力主要受圖像本身特征影響;再讓AI以具體任務指令(如"找出紅色標簽的瓶子")觀察同一圖像,此時注意力會結合任務需求進行調整。通過對比這兩次注意力分布的差異,CARVE能夠準確識別出與任務真正相關的視覺區域。
研究團隊從數學角度證明了這種對比機制的有效性。他們發現AI的注意力分布可以分解為兩個獨立因素的乘積:一個是完全由圖像視覺特征決定的"視覺噪音因子",另一個是由任務需求決定的"語義信號因子"。在通用指令下,語義信號因子趨于均勻分布,注意力主要由視覺噪音主導;而在具體任務指令下,語義信號因子會在相關區域顯著增強。CARVE通過簡單的數學運算,成功分離出這兩個因子,有效抑制了視覺噪音的干擾。
實驗結果顯示,CARVE方法在多個標準測試集上均取得了顯著成效。特別是在處理能力有限的開源模型時,性能提升幅度最高達到75%。以LLAVA1.5-7B模型為例,在專門測試復雜場景小目標定位能力的V*數據集上,其準確率從38.7%提升至66.5%,提升幅度達71.83%。在需要識別圖像中文字信息的TextVQA數據集上,同一模型的準確率也從47.8%提升至58.2%。
與其他視覺增強方法的對比測試進一步驗證了CARVE的優勢。在TextVQA數據集上,CARVE以58.2%的準確率領先于所有對比方法,包括基于SAM分割的方法(49.42%)、YOLO目標檢測方法(48.84%)和CLIP視覺-語言匹配方法(48.55%)。雖然CARVE的處理時間(1.34秒/張)略長于YOLO等快速方法,但顯著快于需要復雜分割的SAM方法(3.33秒/張),且無需任何模型訓練,具有更好的實用性。
研究團隊深入分析了CARVE的工作機制,發現使用網絡深層注意力信息比淺層更有效,這與AI注意力在不同網絡層次的演化規律一致。在淺層網絡中,AI的注意力呈現全局掃描特征;隨著網絡加深,注意力逐漸聚焦到關鍵區域。CARVE通過對比機制,幫助模型在網絡深層實現更有效的注意力收斂。
CARVE方法展現出了良好的魯棒性。研究測試了不同的圖像掩碼生成參數,發現在保留圖像20%-60%區域、選擇2-3個主要區域的設置下,模型性能提升最為穩定。過度激進的掩碼策略(如只保留20%以下區域或僅選擇一個區域)反而會導致性能下降,因為可能丟失重要視覺信息。
盡管CARVE取得了顯著進展,但研究團隊也指出了其局限性。該方法會增加一定的計算開銷,雖然通過早期終止推理和注意力緩存等優化策略,計算效率已得到提升,但在實時應用場景中仍需進一步優化。CARVE的效果依賴于通用指令的選擇,研究團隊通過實驗確定了最優指令,但在不同語言和文化背景下可能需要調整。對于極端復雜的場景,如包含數百個小物體的密集圖像,CARVE可能仍需結合其他技術手段。
這項研究為提升AI視覺推理能力提供了新思路。通過模擬人類"先瀏覽再聚焦"的視覺認知模式,CARVE幫助AI模型在復雜環境中更準確地定位關鍵信息。隨著技術的不斷完善,這類方法有望在醫療影像分析、輔助視覺系統、教育輔導等多個領域發揮重要作用,使AI的視覺理解能力更接近人類水平。