在復雜路況中駕駛時,駕駛員常因視野局限陷入被動:城市路口的車道擁堵難以預判,高速公路的突發減速易引發連鎖反應。為破解這一難題,高德地圖通過空間智能架構升級TrafficVLM交通視覺語言模型,將導航體驗從“局部感知”推向“全局掌控”,重新定義了智能出行的技術邊界。

升級后的TrafficVLM以“交通孿生還原”技術為核心,構建起覆蓋任意區域、任意尺度的動態數字交通系統。無論是北京國貿橋的立體交叉路口,還是廣州老城區的狹窄巷道,系統均能實時生成與現實同步的交通視頻流。這些數據不僅為模型提供訓練素材,更通過云端調度實現分鐘級更新——當3公里外發生追尾事故時,系統可立即捕捉現場畫面,分析擁堵蔓延趨勢,并在駕駛員抵達前推送避險建議:“前方事故導致擁堵,建議提前靠右并線,注意應急車輛通行”。
與傳統導航的“文字提示”不同,TrafficVLM通過視覺語言交互實現決策透明化。用戶點擊導航界面即可切換至事故現場視角,高清畫面中不僅顯示車流動態,更通過深度信息分析還原擁堵空間結構。例如,系統會標注變道時機、減速距離等關鍵參數,幫助駕駛員理解“為何要繞行”而非機械執行指令。這種從“被動接收”到“主動洞察”的轉變,使復雜路況變得可視化、可感知。
技術架構層面,TrafficVLM以通義Qwen-VL為底座,針對交通場景進行專項強化。模型需同時處理兩種視覺模態:一是識別車輛、車道線、信號燈等靜態元素,二是解析車流互動、減速傳導等動態關系。通過海量交通數據的訓練,模型可預測擁堵成因與發展趨勢,形成“感知-分析-決策”的完整閉環。例如,當檢測到某車道車輛頻繁變道猶豫時,系統會結合歷史數據預判擁堵風險,提前調整路線規劃。
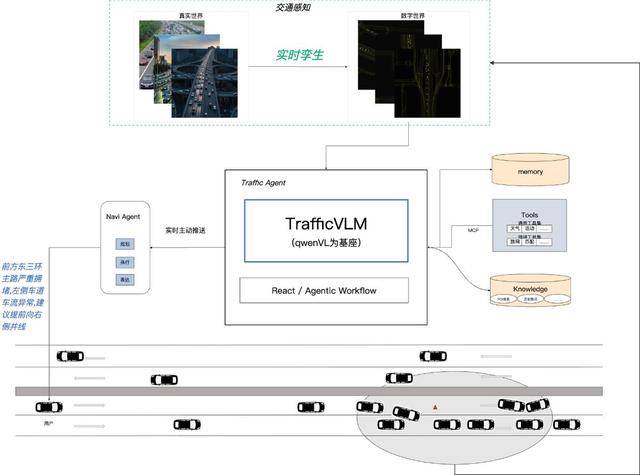
高德團隊透露,交通孿生系統的構建依賴三項核心技術:首先是多尺度空間建模,確保從城市主干道到社區道路的數據全覆蓋;其次是實時視頻流生成,通過云端渲染實現與物理世界的秒級同步;最后是跨模態語義理解,使模型能同時解析圖像、文本與交通流數據。這些技術共同支撐起TrafficVLM的“全知視角”,讓導航從路線指引工具升級為交通決策伙伴。
在實際應用中,該系統已展現出顯著優勢。以演唱會散場為例,模型可同步捕捉鳥巢周邊道路的車流變化,分析觀眾離場路線與公共交通接駁點的疊加影響,動態調整導航策略。這種基于全局數據的決策能力,使復雜場景下的出行效率提升30%以上,同時將突發風險預警時間提前至擁堵形成前5分鐘。
TrafficVLM的突破不僅在于技術融合,更在于重新定義了導航的價值維度。通過將AI決策能力嵌入交通場景,系統將駕駛員從信息過載中解放,轉而提供可解釋、可操作的決策依據。這種“人-機-環境”的協同模式,標志著智能導航從工具屬性向服務屬性的進化,為未來自動駕駛時代的車路協同奠定了基礎。