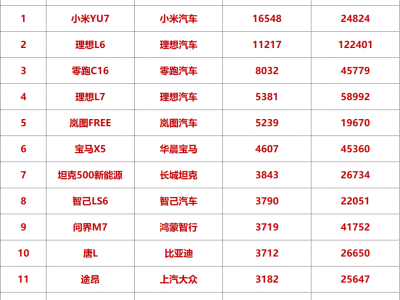
“如果將大模型比作火箭,算力就是它的引擎,但今天我們使用的引擎,啟動鑰匙卻攥在別人手里。”在近期新加坡舉辦的一場閉門論壇上,清華大學教授魏少軍拋出這句比喻,瞬間讓會場陷入短暫的寂靜。他直言不諱地指出,中國AI產業若繼續依賴國外GPU,未來可能面臨“算力心臟驟停”的風險。

這一論斷并非危言聳聽。美國近期出臺的新一輪出口管制政策,將算力硬件的“天花板”進一步壓低。英偉達A100、H100、B100等高端GPU相繼被列入限制清單,國內大模型團隊被迫延長訓練周期30%,或以雙倍價格購買“灰色渠道”產品。更棘手的是,部分云廠商采購的H20芯片被曝存在安全漏洞,某頭部企業不得不緊急下架原計劃上線的千億參數模型,重新拆解硬件架構、清洗數據,直接損失數千萬元,而時間成本的損耗才是真正的“隱形成本”。
魏少軍剖析了問題的根源:GPU并非技術原罪,行業對它的過度依賴才是癥結。英偉達的崛起依賴兩大關鍵節點——2006年CUDA架構的推出,將圖形芯片轉化為通用計算平臺;2010年后AI技術爆發,恰好需要大規模矩陣運算,GPU因此成為“黃金搭檔”。但鮮為人知的是,這一架構最初是為游戲渲染設計,并非為Transformer架構量身定制。如今美國收緊技術出口,中國AI產業才驚覺自己“寄人籬下”,連硬件架構的修改權都未掌握。
破局之道在于“換引擎”。魏少軍提出,與其重復制造“替代版GPU”,不如直接為大模型設計專用ASIC芯片,從晶體管層級嵌入注意力機制的計算特性,實現效率的質的飛躍。這一觀點并非空想,博通近期公布的財報提供了實證:其與北美云巨頭合作的定制AI芯片,推理性能與H100持平,功耗卻降低18%,一舉斬獲百億美元訂單。華爾街的股價反應表明,GPU的壟斷地位已出現裂痕。
國內已有團隊先行試水。今年初,DeepSeek發布的1.3萬億參數MoE模型,訓練全程采用“寒武紀+華為昇騰”混合芯片,未使用任何受限的英偉達產品。據知情人士透露,團隊通過重構指令集層級的算子,延長數據在片內SRAM的停留時間,將帶寬壓力降低5個時鐘周期,最終使訓練成本下降42%。這一案例印證了魏少軍的判斷:當算法與芯片深度耦合,即使使用落后兩代的制程工藝,也能實現“技術逆襲”。
但“換道超車”絕非易事。國產EDA工具目前僅能穩定支持7nm工藝,更先進制程需依賴進口IP;單次流片成本高達5000萬美元,失敗即意味著巨額損失。在軟件層面,TensorFlow和PyTorch雖提供插件接口,但將算子映射至國產ASIC需重寫底層驅動,代碼量以十萬行計。產能問題同樣嚴峻:臺積電先進制程排期已至2026年,國內晶圓廠雖愿接單,但良率提升仍需突破“魔鬼曲線”。任何環節的失誤,都可能導致整個項目停滯。
面對質疑,魏少軍回應直截了當:“繼續追隨GPU,永遠只能看到別人的尾燈。”他建議從推理側芯片切入:這類芯片任務單一、精度要求可控、生態依賴度低,可優先攻克推薦、搜索、安防等高并發場景,通過市場收益反哺訓練芯片研發。華為、阿里、百度近期公布的ASIC路線圖均遵循這一邏輯:先讓推理芯片實現“自我造血”,再逐步向訓練級芯片進軍。
政策層面也在釋放利好。一份內部征求意見稿顯示,央企云采購將設立“國產加速卡配額”,2025年起占比不低于30%,且逐年遞增。考慮到國內公有云增量的一半由央企貢獻,這一政策相當于為國產芯片廠商鎖定百萬級訂單。穩定的訂單需求將促使晶圓廠擴大產能、EDA廠商投入7nm以下工具鏈研發,開發者也更有動力放棄CUDA生態,轉投國產框架。算力自主化的核心,實則是市場信心的重建,而信心需要訂單的持續滋養。
深夜的實驗室里,工程師仍在調試7nm芯片版圖,仿真程序一遍遍運行;產品經理將新出爐的推理卡插入服務器,風扇的轟鳴聲如同起跑的號角。他們清楚,自己書寫的不僅是代碼,更是中國AI能否將“算力心臟”移植回本土的說明書。英偉達的GPU仍是優秀工具,但已不再是唯一選擇。當新一批流片數據送達魏少軍的郵箱,中國AI的“新引擎”離首次點火又近了一步。