硅谷如今炙手可熱的,不再是提示詞工程,而是上下文工程(Context Engineering)!

還有Shopify CEO Tobias Lütke稱,自己更喜歡「上下文工程」,因其準確描述了一個核心技能——
通過為任務提供完整的背景信息,讓大模型能夠合理解決問題的藝術。

一夜之間,「上下文工程」紅遍全網,究竟是為什么?

上下文工程,一夜爆紅
這背后原因,離不開AI智能體的興起。
OpenAI總裁Greg Brockman多次公開表示,「2025年,是AI智能體的元年」。

決定智能體成功或失敗最關鍵的因素,是提供的「上下文質量」。也就是說,加載到「有限工作記憶」中的信息愈加重要。
大多數AI智能體失敗的案例,不是模型的失敗,而是上下文的失敗!
那么,什么是上下文?
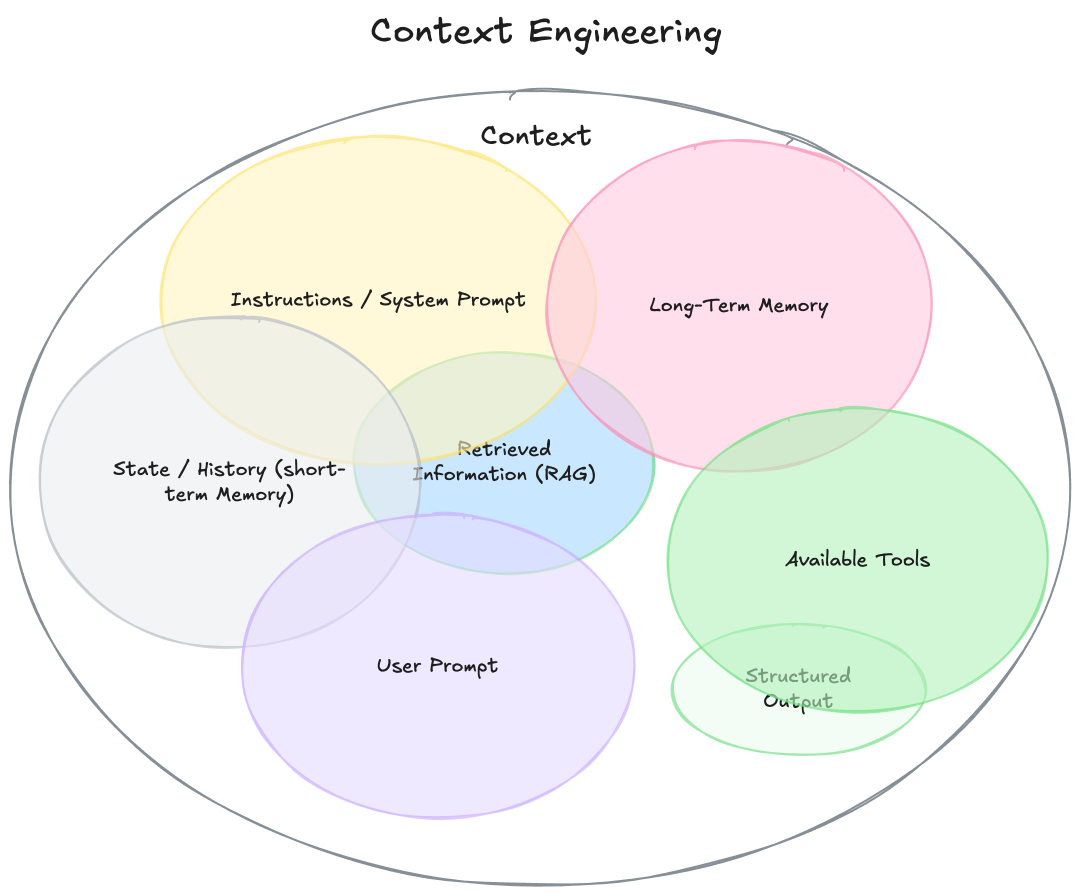
要理解「上下文工程」,首先需要擴展「上下文」的定義。
它不僅僅是你發送給LLM的單一提示,可以將其視為「模型再生成響應之前,看到的所有內容」,如下:
指令/系統提示:定義模型在對話中行為的初始指令集,可以/應該包括示例、規則等。
用戶提示:用戶的即時任務或問題。
狀態/歷史(短期記憶):當前對話,包括用戶和模型的響應,截至此刻。
長期記憶:跨多次之前對話收集的持久知識庫,包含學習到的用戶偏好、過去項目的摘要或要求記住以備將來使用的事實。
檢索信息(RAG):外部、實時的知識,來自文檔、數據庫或API的相關信息,用于回答特定問題。
可用工具:模型可以調用的所有功能或內置工具的定義,比如check_inventory、send_email。
結構化輸出:模型響應格式的定義,例如JSON對象。
可以看出,與專注于在單一本文字符串中,精心構建完美指令的「提示詞工程」不同,「上下文工程」的范疇要廣泛得多。

簡單來說:
「上下文工程」是一門學科,它致力于設計和構建動態系統。
這些系統能夠在恰當的時機、以恰當的格式,提供恰當的信息和工具,從而讓LLM擁有完成任務所需的一切。
以下是「上下文工程」的所有特點
· 它是一個系統,而非一個字符串:上下文并非一個靜態的提示詞模板,而是一個系統的輸出,這個系統在對LLM進行主調用之前就已經運行。
· 它是動態的:上下文是即時生成的,為當前任務量身定制。比如,某個請求可能需要的是日歷數據,而另一個請求則可能需要電子郵件內容或網絡搜索結果。
· 它強調在恰當時機提供恰當信息與工具:其核心任務是確保模型不會遺漏關鍵細節(謹記「垃圾進,垃圾出」原則)。這意味著只在必要且有益的情況下,才向模型提供知識(信息)和能力(工具)。
· 它注重格式:信息的呈現方式至關重要。一份簡潔的摘要遠勝于原始數據的羅列;一個清晰的工具接口定義也遠比一條模糊的指令有效。


是一門科學,也是一門藝術
人們往往將提示詞(prompt),聯想為日常使用中——發給LLM的簡短任務描述。
然而,在任何一個工業級的 LLM 應用中,上下文工程都是一門精深的科學,也是一門巧妙的藝術。
其核心在于,為下一步操作,用恰到好處的信息精準填充上下文窗口。

說它是科學,是因為要做好這一點,需要綜合運用一系列技術,其中包括:
任務描述與解釋、少樣本學習示例、RAG(檢索增強生成)、相關的(可能是多模態的)數據、工具、狀態與歷史記錄、信息壓縮等等。
信息太少或格式錯誤,LLM就沒有足夠的上下文來達到最佳性能;
信息太多或關聯性不強,又會導致LLM的成本上升、性能下降。
要做好這一點是頗為復雜的。
說它是藝術,則是因為其中需要依賴開發者對大模型「脾性」的直覺把握和引導。
除了上下文工程本身,一個LLM應用還必須做到:
將問題恰到好處地拆解成控制流
精準地填充上下文窗口
將調用請求分派給類型和能力都合適的LLM
處理「生成-驗證」的UIUX流程
以及更多——例如安全護欄、系統安全、效果評估、并行處理、數據預取等等…
因此,「上下文工程」只是一個正在興起的、厚重且復雜的軟件層中的一小部分。
這個軟件層負責將單個的LLM調用,以及更多其他操作整合協調,從而構建出完整的LLM應用。
有網友對此調侃道,上下文工程,是全新的「氛圍編程」。
你會用一個提示詞去問LLM「天空為什么是藍色的」。但應用程序呢,則是需要為大模型構建上下文,才能解決那些為它量身定制的任務。
智能體成敗,全靠它了
其實,打造真正高效的AI智能體秘訣,關鍵不在于編寫的代碼有多復雜,而在于你所提供的上下文有多優質。
一個效果粗糙的演示產品,同一個表現驚艷的智能體,其根本區別就在于提供的上下文質量。
想象一下,一個AI助理需要根據一封簡單的郵件來安排會議:
嘿,想問下你明天有空簡單碰個頭嗎?
「粗糙的演示」智能體獲得的上下文很貧乏。它只能看到用戶的請求,別的什么都不知道。
它的代碼可能功能齊全——調用一個LLM并獲得響應,但輸出的結果卻毫無幫助,而且非常機械化:
感謝您的消息。我明天可以。請問您想約在什么時間?
接下來,再看看由豐富的上下文加持的驚艷智能體。
其代碼的主要任務并非是思考如何回復,而是去收集LLM達成目標所需的信息。在調用LLM之前,你會將上下文擴展,使其包含:
代碼的主要工作,不是決定如何響應,而是收集LLM完成目標所需的信息。
在調用LLM之前,你會擴展上下文,包括:
日歷信息:顯示你全天都排滿了
與此人的過去郵件:用來判斷應該使用何種非正式語氣
聯系人列表:用來識別出對方是一位重要合作伙伴
用于send_invite或send_email的工具
然后,你就可以生成這樣的回復:
嘿,Jim!我明天日程完全排滿了,會議一個接一個。周四上午我有空,你看方便嗎?邀請已經發給你了,看這個時間行不行哈。
這種驚艷的效果,其奧秘不在于模型更智能,或算法更高明,而在于為正確的任務提供了正確的上下文。
這正是「上下文工程」將變得至關重要的原因。
所以說,智能體的失敗,不只是模型的失敗,更是上下文的失敗。
要構建強大而可靠的 AI 智能體,我們正逐漸擺脫對尋找「萬能提示詞」,或依賴模型更新的路徑。
這一點,深得網友的認同。

其核心在于對上下文的工程化構建:即在恰當的時機、以恰當的格式,提供恰當的信息和工具。
這是一項跨職能的挑戰,它要求我們深入理解業務用例、明確定義輸出,并精心組織所有必要信息,從而使LLM能夠真正「完成任務」。
最后,借用網友一句話,「記憶」才是AGI拼圖的最后一塊。