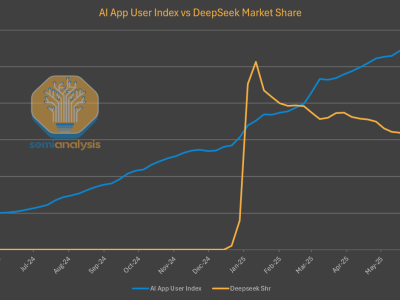
在AI領(lǐng)域,一場圍繞性能與價格平衡的較量正在悄然上演。曾經(jīng)以高性價比震撼市場的中國大模型DeepSeek,近期在用戶留存和官網(wǎng)流量上遭遇了滑鐵盧,市場份額持續(xù)下滑,引發(fā)業(yè)界廣泛關(guān)注。
DeepSeek R1自發(fā)布以來,憑借與OpenAI相媲美的推理能力和低廉90%的價格,迅速在AI圈走紅,甚至一度影響了西方資本市場。然而,隨著時間的推移,這款模型在用戶端的表現(xiàn)卻出現(xiàn)了明顯下滑。盡管在第三方平臺上,DeepSeek R1和V3模型的使用量持續(xù)增長,但自家托管模型的用戶增長卻顯得乏力。
深入分析發(fā)現(xiàn),這一變化背后隱藏著復(fù)雜的“Token經(jīng)濟(jì)學(xué)”考量。Token作為AI模型的基本單元,其價格并非孤立存在,而是模型提供商在平衡硬件、模型配置以及各項性能指標(biāo)后的結(jié)果。這些性能指標(biāo)包括延遲、吞吐量和上下文窗口大小,它們共同決定了模型服務(wù)的用戶體驗和成本效益。
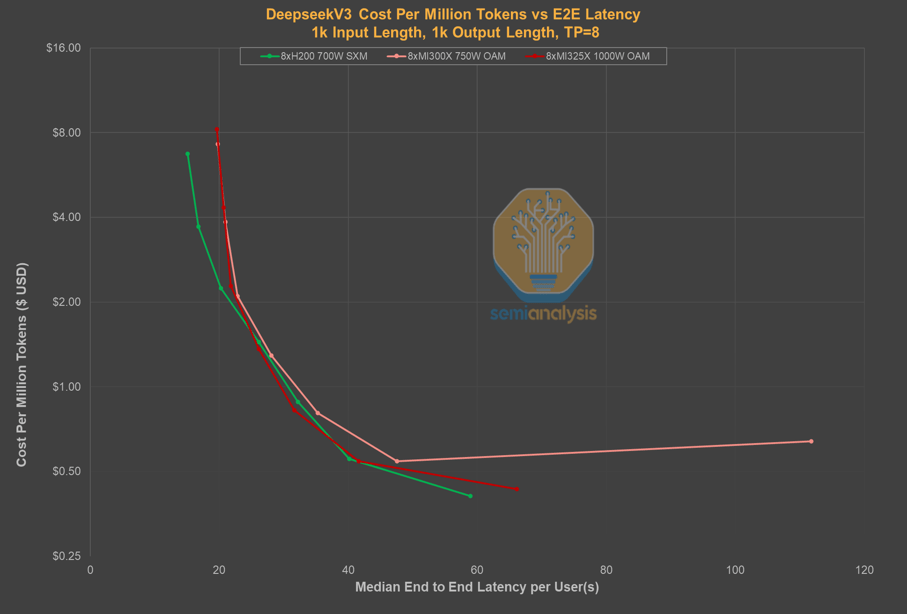
DeepSeek為了提供低價模型,在延遲和上下文窗口大小上做出了權(quán)衡。用戶往往需要等待數(shù)秒才能收到模型返回的第一個Token,同時較小的上下文窗口限制了模型在編程等場景的應(yīng)用。相比之下,其他服務(wù)商如Parasail、Friendli等,在提供近乎零延遲體驗的同時,價格幾乎沒有差別。微軟Azure雖然價格較高,但延遲卻大幅減少。
DeepSeek采用的極高批處理方式,雖然最大限度地減少了用于模型推理和對外服務(wù)的計算資源消耗,從而將更多算力保留用于內(nèi)部研發(fā),但這一戰(zhàn)略選擇也導(dǎo)致了用戶體驗的下降。終端用戶需要承受更高的延遲和更慢的吞吐量,從而影響了模型的普及和市場份額。
值得注意的是,盡管DeepSeek在自家平臺上遇冷,但在全球市場上,其開源策略卻贏得了廣泛認(rèn)可。通過讓其他云服務(wù)商托管其模型,DeepSeek不僅節(jié)省了寶貴的計算資源,還贏得了全球用戶的認(rèn)知度和基礎(chǔ)。這一策略與中國AI生態(tài)系統(tǒng)在模型服務(wù)方面的限制有關(guān),但也反映了DeepSeek對實現(xiàn)通用人工智能(AGI)的堅定決心。
與此同時,另一家AI公司Anthropic也面臨著類似的算力挑戰(zhàn)。盡管其在編程領(lǐng)域取得了顯著成功,如Cursor應(yīng)用的廣泛應(yīng)用和Claude Code的推出,但算力上的局限仍然限制了其模型的生成速度和用戶體驗。為了應(yīng)對這一挑戰(zhàn),Anthropic正在積極尋求更多算力資源,并與亞馬遜達(dá)成了協(xié)議。
在這場AI領(lǐng)域的較量中,DeepSeek和Anthropic的故事為我們提供了寶貴的啟示。在追求高性價比的同時,如何平衡用戶體驗和算力資源,將成為未來AI模型提供商需要深入思考的問題。而隨著“GPT套殼”應(yīng)用的迅速流行和主流市場的認(rèn)可,AI模型的價值鏈和分發(fā)模式也將迎來更加深刻的變革。