在人工智能領(lǐng)域,超級智能(Superintelligence)的概念正逐漸從科幻走向現(xiàn)實(shí),它超越了通用人工智能(AGI)的范疇,預(yù)示著一種在各方面能力都遠(yuǎn)超人類的智能形態(tài)。近日,科技巨頭meta宣布斥資數(shù)十億美元秘密建立超級智能實(shí)驗(yàn)室,此舉引發(fā)了業(yè)界的廣泛關(guān)注。
meta的大手筆投入只是冰山一角,OpenAI、Anthropic和Google DeepMind等頭部企業(yè)也紛紛表達(dá)了構(gòu)建超級智能機(jī)器的雄心壯志。OpenAI的首席執(zhí)行官Sam Altman更是直言不諱,他認(rèn)為構(gòu)建超級智能是一個工程問題,而非純粹的科學(xué)難題,這似乎暗示了他們已經(jīng)掌握了通往超級智能的關(guān)鍵路徑。
然而,對于如何實(shí)現(xiàn)超級智能,業(yè)界內(nèi)部存在著激烈的爭議。meta AI的研究員Jack Morris就對當(dāng)前基于大語言模型(LLM)的強(qiáng)化學(xué)習(xí)(RL)路徑提出了質(zhì)疑。他認(rèn)為,盡管LLM在訓(xùn)練分布內(nèi)的任務(wù)上表現(xiàn)出色,但它們并不足以構(gòu)成一個單一的超級智能模型。
Morris在博客“Superintelligence, from First Principles”中探討了構(gòu)建超級智能的三種可能方式,包括完全由監(jiān)督學(xué)習(xí)(SL)、來自人類驗(yàn)證者的RL以及來自自動驗(yàn)證器的RL。他指出,將非文本數(shù)據(jù)整合到模型中并未帶來整體性能的提升,因?yàn)槿祟愖珜懙奈谋揪哂心撤N內(nèi)在價值,這是其他模態(tài)數(shù)據(jù)所無法比擬的。

在Morris看來,數(shù)據(jù)是實(shí)現(xiàn)超級智能的關(guān)鍵。他強(qiáng)調(diào),目前最好的系統(tǒng)都依賴于從互聯(lián)網(wǎng)的文本數(shù)據(jù)中學(xué)習(xí),而非文本數(shù)據(jù)如圖像、視頻等并未對提升LLM的智能水平產(chǎn)生顯著影響。這一觀點(diǎn)引發(fā)了關(guān)于數(shù)據(jù)類型的深入討論,即文本數(shù)據(jù)是否真的是實(shí)現(xiàn)超級智能的唯一或最佳選擇。
除了數(shù)據(jù)類型,學(xué)習(xí)算法也是實(shí)現(xiàn)超級智能的關(guān)鍵因素之一。在機(jī)器學(xué)習(xí)領(lǐng)域,SL和RL是兩種基本的學(xué)習(xí)方法。SL通過訓(xùn)練模型以增加某些示例數(shù)據(jù)的概率,而RL則涉及從模型中生成數(shù)據(jù),并根據(jù)其采取的“良好”行動給予獎勵。
對于SL路徑,一些人認(rèn)為通過大量的SL,特別是以“next-token prediction”的形式,可能導(dǎo)致超級智能AI的出現(xiàn)。然而,這種邏輯也面臨著挑戰(zhàn)。盡管我們已經(jīng)創(chuàng)建了在next-token prediction方面遠(yuǎn)超人類水平的系統(tǒng),但這些系統(tǒng)仍無法展現(xiàn)人類級別的通用智能。隨著模型規(guī)模的擴(kuò)大,數(shù)據(jù)不足和硬件限制也成為了制約SL路徑進(jìn)一步發(fā)展的瓶頸。
相比之下,RL路徑提供了通過反饋而非僅依賴演示進(jìn)行學(xué)習(xí)的可能性。然而,RL也面臨著諸多挑戰(zhàn),如冷啟動問題、獎勵稀疏性等。為了克服這些挑戰(zhàn),人們開始探索結(jié)合SL與RL的方法,即先通過SL進(jìn)行預(yù)訓(xùn)練,然后利用RL進(jìn)行微調(diào)。

在結(jié)合SL與RL的方法中,來自人類驗(yàn)證者的RL和來自自動驗(yàn)證器的RL是兩種主要的方式。前者依賴于人類提供的獎勵信號來訓(xùn)練模型,后者則利用自動驗(yàn)證器來評估模型的性能并給予獎勵。盡管這兩種方式都具有一定的潛力,但它們也面臨著各自的挑戰(zhàn)。
對于來自人類驗(yàn)證者的RL,數(shù)據(jù)收集成本高昂,且人類判斷的主觀性也可能影響模型的訓(xùn)練效果。而對于來自自動驗(yàn)證器的RL,雖然可以去除人類的參與,但目前可驗(yàn)證的任務(wù)類型有限,且RL在可驗(yàn)證任務(wù)上的遷移能力尚不清楚。
盡管如此,業(yè)界對于基于LLM的RL仍然充滿了期待。OpenAI利用可驗(yàn)證獎勵強(qiáng)化學(xué)習(xí)(RLVR)訓(xùn)練的o1模型已經(jīng)取得了顯著的成果,它能夠通過更長時間的思考產(chǎn)生更優(yōu)的輸出。這一突破讓人們看到了利用RL實(shí)現(xiàn)超級智能的可能性。
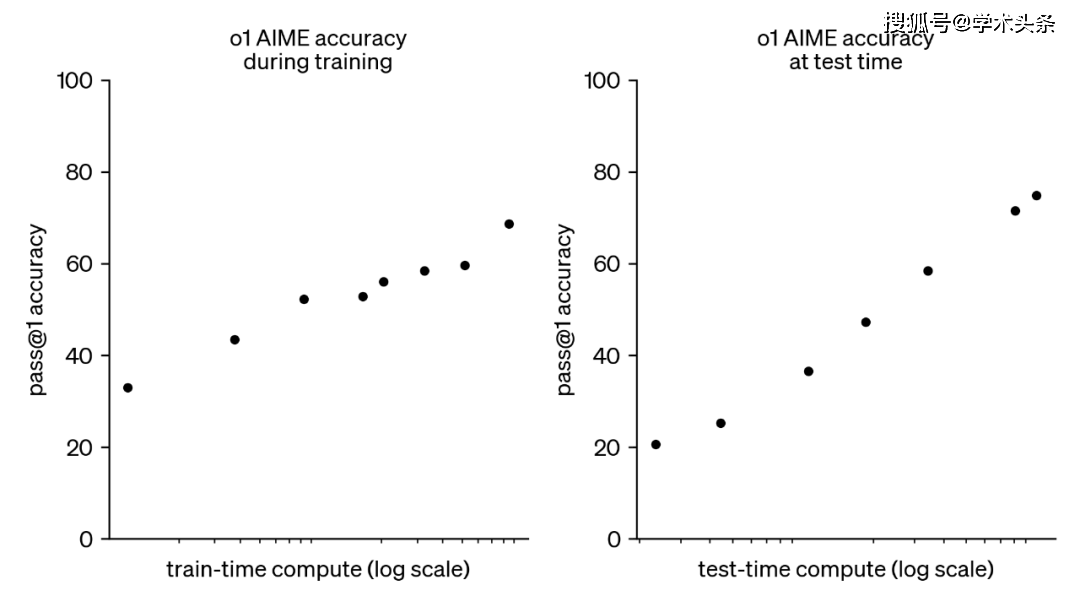
然而,通往超級智能的道路仍然漫長且充滿挑戰(zhàn)。盡管我們已經(jīng)取得了一些進(jìn)展,但距離實(shí)現(xiàn)真正的超級智能還有很長的路要走。在這個過程中,我們需要不斷探索新的方法和技術(shù),同時也需要保持謹(jǐn)慎和謙遜的態(tài)度,以應(yīng)對可能出現(xiàn)的各種風(fēng)險和挑戰(zhàn)。