近期,科技界傳來一則引人注目的消息,英偉達研究團隊在人工智能領域取得了重要突破。據科技媒體marktechpost報道,英偉達不僅推出了一種名為ProRL的強化學習方法,還成功開發出了目前全球頂尖的1.5B參數推理模型——Nemotron-Research-Reasoning-Qwen-1.5B。
推理模型,作為專門設計的人工智能系統,其核心在于通過復雜的長鏈推理過程,得出最終的答案。這一技術在近年來備受關注,而強化學習在這一過程中的作用更是不可忽視。此前,DeepSeek和Kimi等團隊已采用可驗證獎勵的強化學習方法(RLVR),推動了GRPO、Mirror Descent和RLOO等算法的發展。
然而,盡管強化學習在理論上被認為能夠提升大型語言模型(LLM)的推理能力,但實際應用中卻面臨諸多挑戰。現有研究表明,RLVR在pass@k指標上并未顯著優于基礎模型,這顯示出推理能力的擴展存在局限性。當前的研究大多聚焦于數學等特定領域,導致模型過度訓練,限制了其探索新領域的潛力。同時,強化學習的訓練步數通常較短,往往僅數百步,這使得模型難以充分發展新的能力。
為了克服這些難題,英偉達研究團隊推出了ProRL方法。他們不僅將強化學習的訓練時間延長至超過2000步,還大大擴展了訓練數據的范圍,涵蓋了數學、編程、STEM、邏輯謎題和指令遵循等多個領域,共計13.6萬個樣本。這一舉措旨在提升模型的泛化能力,使其能夠在不同領域都表現出色。
在ProRL方法的基礎上,英偉達團隊采用了verl框架和改進的GRPO方法,成功開發出了Nemotron-Research-Reasoning-Qwen-1.5B模型。這一模型在多項基準測試中均表現出色,超越了基礎模型DeepSeek-R1-1.5B,甚至在某些方面優于更大的DeepSeek-R1-7B模型。
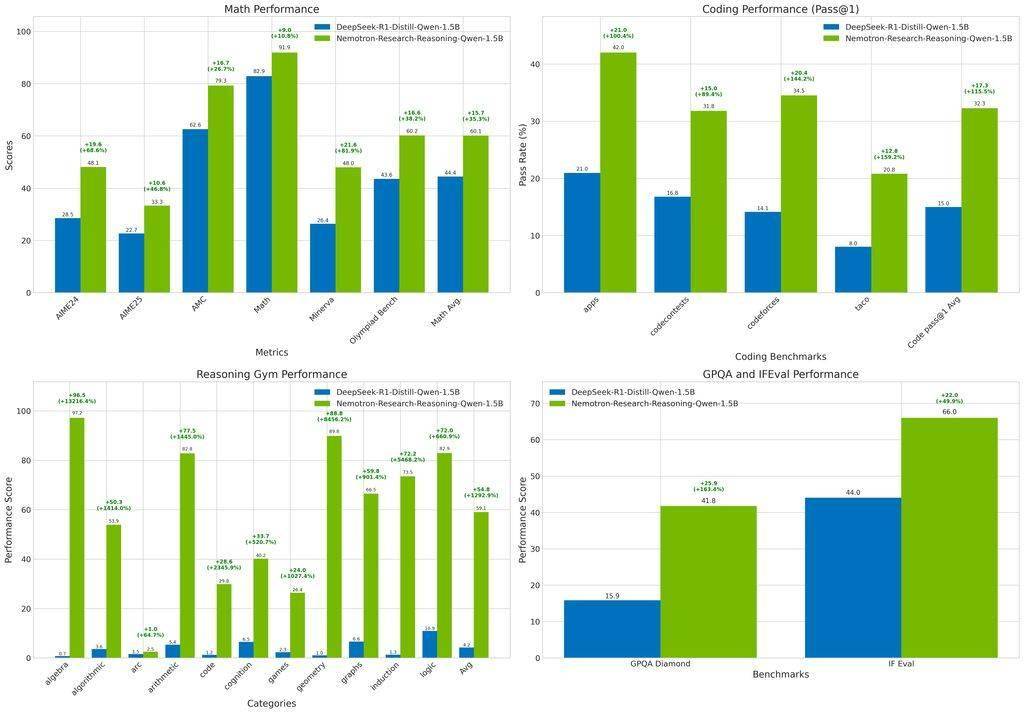
測試結果顯示,Nemotron-Research-Reasoning-Qwen-1.5B模型在數學領域實現了平均15.7%的提升,編程任務的pass@1準確率提高了14.4%,在STEM推理和指令遵循方面分別提升了25.9%和22.0%,邏輯謎題的獎勵值更是提升了驚人的54.8%。這一系列數據充分展示了該模型在不同領域中的強大推理能力和泛化性能。
英偉達的這一突破無疑為人工智能領域帶來了新的希望和可能。隨著技術的不斷進步和應用的不斷拓展,我們有理由相信,未來將有更多像Nemotron-Research-Reasoning-Qwen-1.5B這樣的優秀模型涌現出來,為人類社會帶來更多的便利和價值。