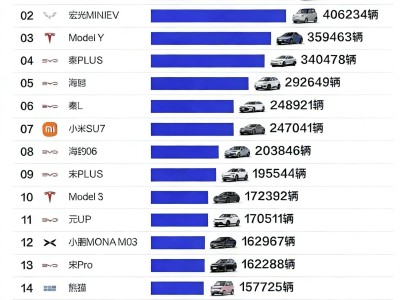
摩爾線程在近日舉辦的MUSA開發(fā)者大會上,正式推出全新“花港”架構(gòu),并同步完成MUSA 5.0全棧軟件升級。此次發(fā)布的核心亮點(diǎn)包括兩款基于新架構(gòu)的芯片——“華山”與“廬山”,分別聚焦AI計(jì)算與圖形渲染領(lǐng)域,標(biāo)志著國產(chǎn)GPU在技術(shù)自主化進(jìn)程中邁出關(guān)鍵一步。
作為花港架構(gòu)的首款芯片,“華山”以AI訓(xùn)推一體化為核心定位,通過架構(gòu)升級實(shí)現(xiàn)了多項(xiàng)性能突破。其內(nèi)置的新一代張量計(jì)算引擎支持TF32/FP16/INT8全精度矩陣運(yùn)算,并針對FP6/FP4低精度計(jì)算進(jìn)行優(yōu)化,配合新增的TCE-PAIR數(shù)據(jù)重用模式,顯著提升張量運(yùn)算效率。在硬件設(shè)計(jì)上,該芯片集成MTFP8/6/4混合低精度計(jì)算技術(shù),同時(shí)兼容MXFP與NVFP兩種計(jì)算標(biāo)準(zhǔn),為AI模型訓(xùn)練與推理提供靈活支持。
針對超大規(guī)模AI計(jì)算場景,“華山”芯片展現(xiàn)出強(qiáng)大的擴(kuò)展能力。其搭載的新一代Scale-up系統(tǒng)支持MTLink 4.0協(xié)議與多種以太網(wǎng)標(biāo)準(zhǔn),可適配不同廠商的Scale-up交換機(jī),片間互聯(lián)帶寬達(dá)1314GB/s。這一特性使其具備支撐超十萬卡級AI工廠的潛力,通過支持SHARP網(wǎng)絡(luò)協(xié)議優(yōu)化集體通信效率,滿足大模型訓(xùn)練對算力集群的嚴(yán)苛需求。
另一款芯片“廬山”則專注于高性能圖形渲染領(lǐng)域。依托花港架構(gòu)的新一代指令集,該芯片在算力密度上實(shí)現(xiàn)50%提升,能效比達(dá)到前代產(chǎn)品的10倍。其內(nèi)置的第一代AI生成式渲染架構(gòu)(AGR)與第二代光追硬件加速引擎形成協(xié)同,可完美兼容DirectX 12 Ultimate標(biāo)準(zhǔn),為游戲、影視等場景提供真實(shí)光影效果。在渲染管線優(yōu)化方面,UNITE架構(gòu)通過動態(tài)任務(wù)分配機(jī)制,有效平衡幾何處理、像素著色與光追計(jì)算負(fù)載。
值得關(guān)注的是,花港架構(gòu)在光線追蹤技術(shù)上取得重大突破。全新設(shè)計(jì)的光追硬件加速引擎支持全場景光線遍歷求交運(yùn)算,相比前代春曉架構(gòu)性能提升達(dá)50倍。這一進(jìn)步不僅縮短了實(shí)時(shí)渲染的延遲,還為建筑可視化、工業(yè)設(shè)計(jì)等專業(yè)領(lǐng)域提供高效解決方案。據(jù)技術(shù)白皮書披露,該引擎通過硬件級優(yōu)化減少了軟件層面的計(jì)算開銷,使得復(fù)雜場景的光追渲染效率得到質(zhì)的提升。
據(jù)現(xiàn)場技術(shù)演示顯示,搭載兩款新芯片的硬件產(chǎn)品已完成原型驗(yàn)證,預(yù)計(jì)將于明年正式投入商用。摩爾線程透露,新架構(gòu)在軟件生態(tài)層面已完成與主流AI框架及圖形API的適配,開發(fā)者可通過MUSA工具鏈快速遷移現(xiàn)有應(yīng)用。此次發(fā)布標(biāo)志著國產(chǎn)GPU在架構(gòu)設(shè)計(jì)、性能指標(biāo)與生態(tài)兼容性等方面達(dá)到國際先進(jìn)水平,為人工智能與數(shù)字內(nèi)容產(chǎn)業(yè)提供新的算力選擇。