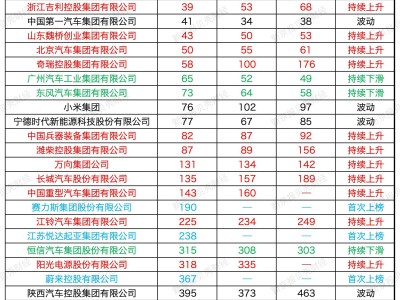
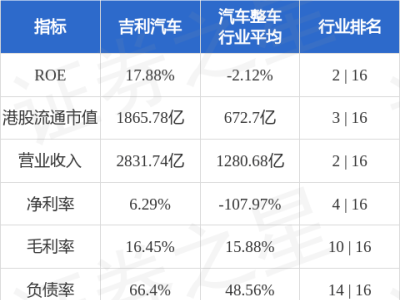
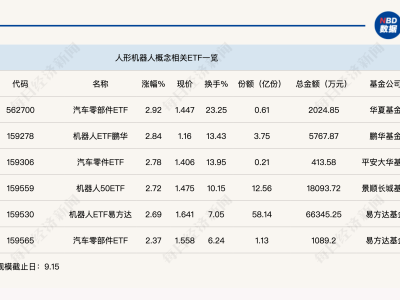
OpenAI近期對evals工具進行了關鍵功能升級,新增原生音頻輸入與評分模塊,為語音技術開發者開辟了更高效的評估路徑。此次更新突破了傳統語音模型評估需依賴文本轉錄的局限,允許直接對模型輸出的音頻內容進行質量分析,顯著簡化了語音識別與生成類應用的開發流程。
開發者通過新功能可直接上傳待測音頻文件,系統將自動完成從輸入到評分的全流程處理。這種"端到端"的評估方式不僅減少了中間數據轉換環節,更通過保留原始音頻特征提升了評估精度。對于需要反復調優語音交互系統的團隊而言,該功能可大幅縮短測試周期,同時確保評估結果更貼近實際應用場景。
實際應用層面,該技術已展現出廣泛價值。在智能語音助手開發中,開發者可精準檢測語音指令的識別準確率;語音識別系統可通過對比標準音頻與模型輸出,量化識別誤差;音頻內容生成領域則能直接評估合成語音的自然度與情感表現。這些場景的評估效率均因原生音頻支持得到顯著提升。