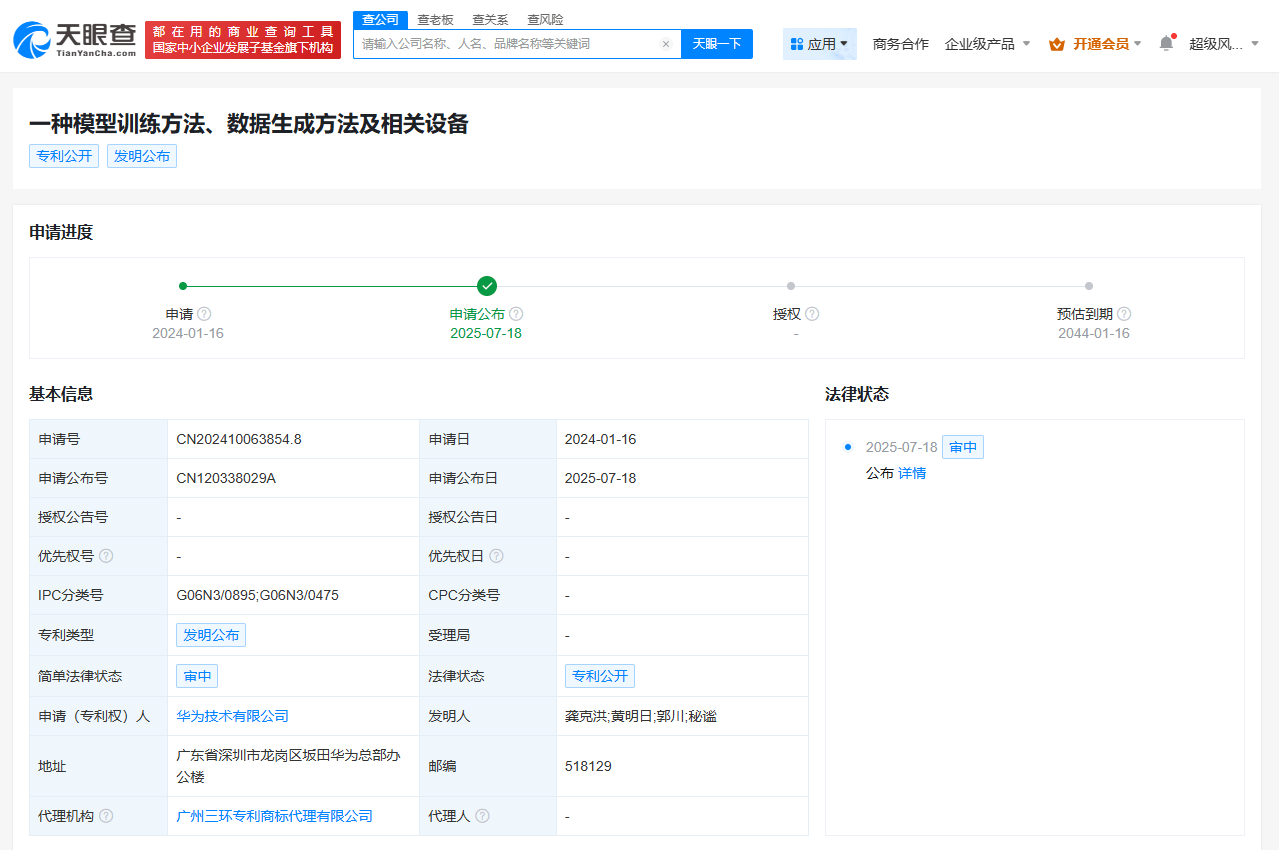
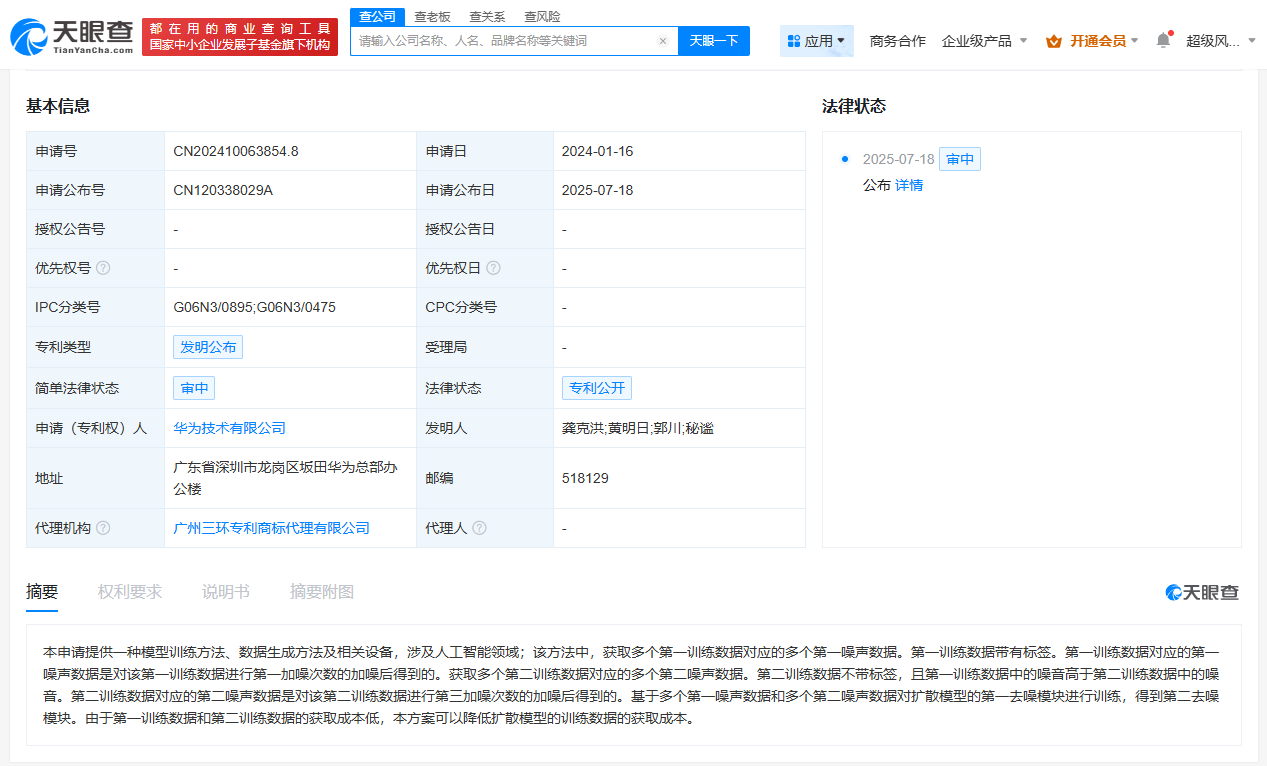
近期,華為技術(shù)有限公司在人工智能領(lǐng)域的一項新專利引起了廣泛關(guān)注。該專利名為“一種創(chuàng)新的模型與數(shù)據(jù)生成方法及相關(guān)設(shè)備”,并于7月18日正式公布。
據(jù)悉,這一專利申請涉及的技術(shù)方法頗為獨特。具體而言,該方法首先獲取一批帶有標(biāo)簽的第一訓(xùn)練數(shù)據(jù),并針對這些數(shù)據(jù)生成相應(yīng)的第一噪聲數(shù)據(jù)。這些噪聲數(shù)據(jù)是通過對第一訓(xùn)練數(shù)據(jù)進(jìn)行特定次數(shù)的加噪處理得到的。還獲取了一批不帶標(biāo)簽的第二訓(xùn)練數(shù)據(jù),這些數(shù)據(jù)本身的噪聲水平相對較低。為了構(gòu)建更為復(fù)雜的訓(xùn)練環(huán)境,第二訓(xùn)練數(shù)據(jù)同樣經(jīng)歷了加噪處理,生成了第二噪聲數(shù)據(jù)。
尤為值得注意的是,該方法巧妙利用了兩種訓(xùn)練數(shù)據(jù)的不同特性。第一訓(xùn)練數(shù)據(jù)雖然帶有標(biāo)簽,但其包含的噪聲較高;而第二訓(xùn)練數(shù)據(jù)雖然無標(biāo)簽,但噪聲水平相對較低。通過結(jié)合這兩種數(shù)據(jù)及其對應(yīng)的噪聲數(shù)據(jù),華為的技術(shù)團(tuán)隊對擴(kuò)散模型中的第一去噪模塊進(jìn)行了訓(xùn)練,并最終得到了優(yōu)化后的第二去噪模塊。
華為在人工智能領(lǐng)域的持續(xù)探索和創(chuàng)新,無疑為行業(yè)的發(fā)展注入了新的活力。這一新專利的公布,不僅展示了華為在技術(shù)研發(fā)方面的深厚實力,也為未來人工智能技術(shù)的廣泛應(yīng)用奠定了堅實基礎(chǔ)。