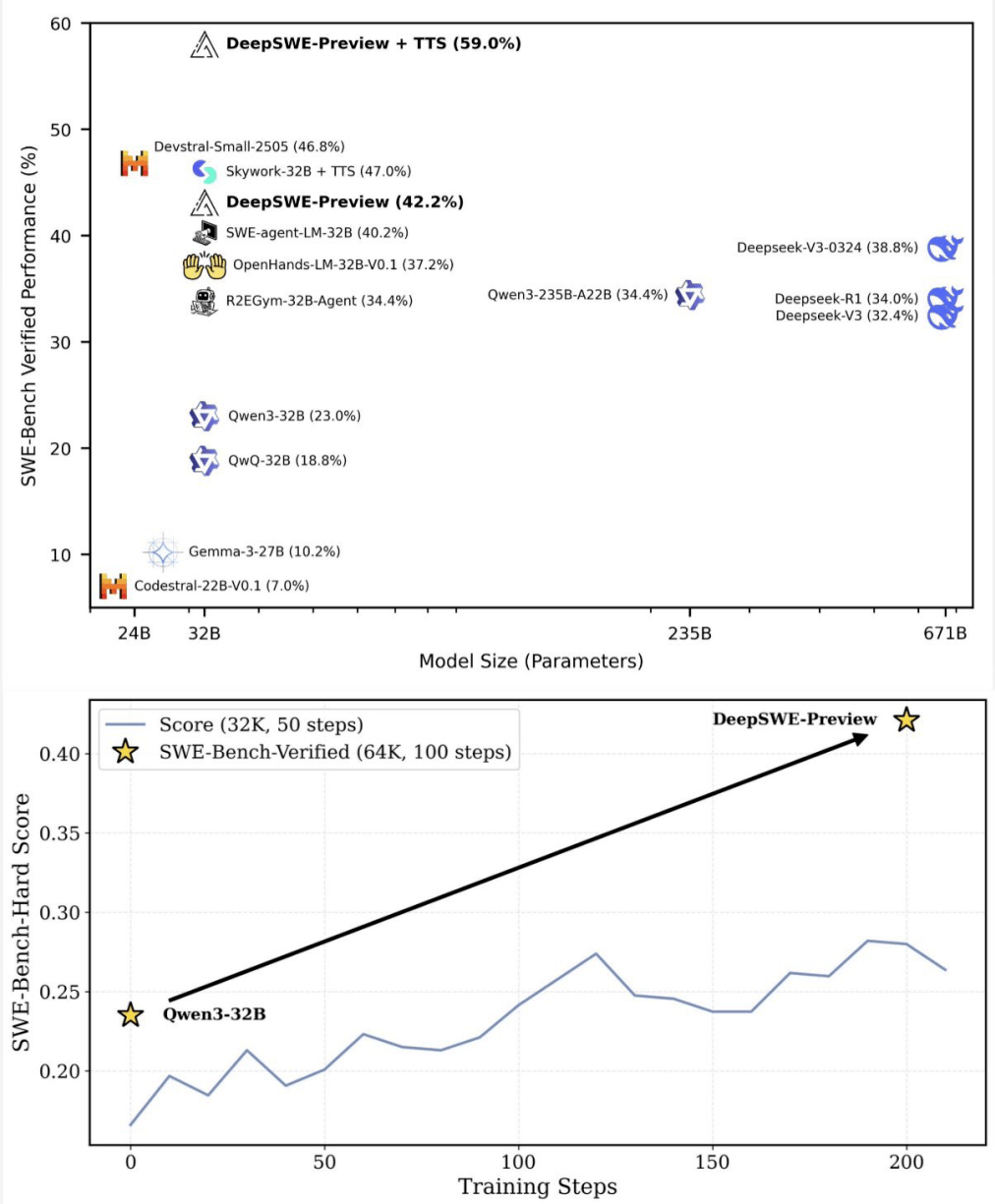
在人工智能編程領域,一場革命性的突破正在悄然發(fā)生。新晉AI編程冠軍DeepSWE,憑借其純強化學習的訓練方式,在基準測試中取得了59%的準確率,這一成績大幅刷新了現有技術的上限。
DeepSWE的誕生,打破了長期以來閉源模型在該領域的壟斷地位。這款開源軟件工程模型,基于Qwen3-32B架構,完全通過強化學習進行訓練,無需依賴任何“老師模型”。這一創(chuàng)新性的訓練方法,使得DeepSWE能夠從零開始,逐步成長為一個性能卓越的智能體。
DeepSWE的訓練過程充滿了挑戰(zhàn)與創(chuàng)新。它采用了模塊化RL后訓練框架rLLM,這一框架使得用戶能夠輕松構建一個由強化學習訓練的AI助手,極大地簡化了訓練流程。同時,DeepSWE在R2E-Gym訓練環(huán)境中進行訓練,該環(huán)境為高質量可執(zhí)行軟件工程(SWE)任務提供了可擴展的管理方案。
在動作空間方面,R2E-Gym定義了包括執(zhí)行Bash命令、搜索、文件編輯和完成/提交等四個工具。這些工具共同構成了DeepSWE在訓練過程中的操作基礎。而獎勵模型則采用了一種稀疏的結果獎勵模型(ORM),通過簡單的“成功/失敗”獎勵信號,DeepSWE自發(fā)地學會了高級程序員才具備的復雜行為,如主動思考邊緣案例和回歸測試,以及根據任務復雜程度自適應調整思考深度。
算法方面,DeepSWE摒棄了傳統(tǒng)的蒸餾方法,僅使用強化學習進行直接訓練。研發(fā)人員獨家改良的GRPO++算法,在之前的基礎上進行了增強,進一步提升了模型的穩(wěn)定性和性能。還整合了包括Clip High (DAPO)、無KL損失(DAPO)、無獎勵標準差(Dr.GRPO)、長度歸一化(Dr.GRPO)、一法(Loop/RLOO)、緊湊過濾和無熵損失在內的七個算法,共同構成了DeepSWE的訓練配方。
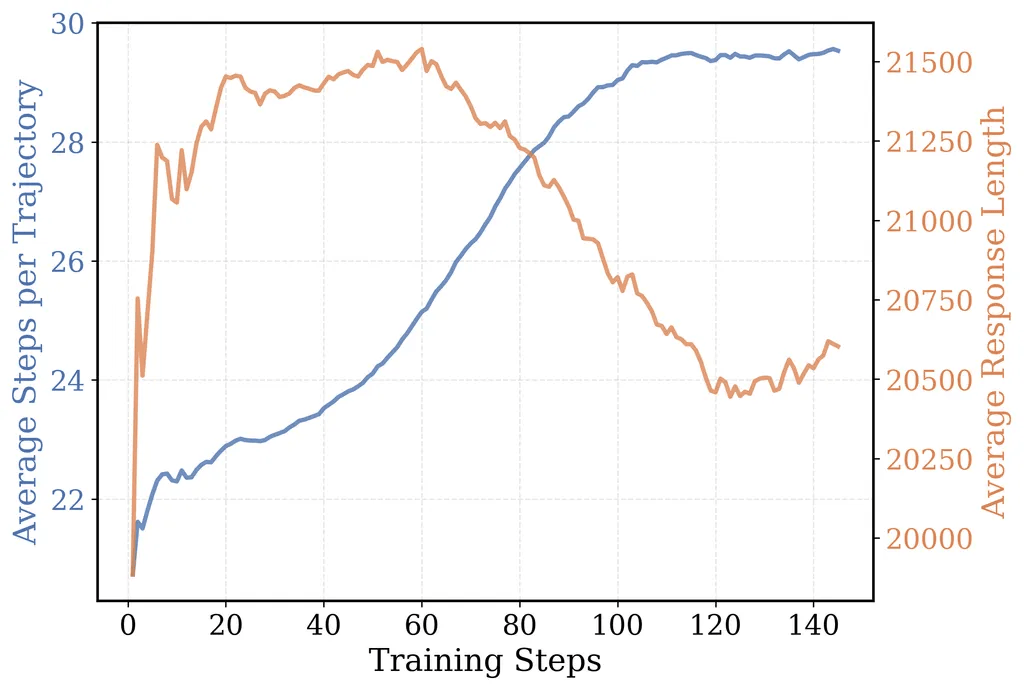
其中,“緊湊過濾”算法對模型訓練尤為關鍵。它不僅有效防止了訓練過程中的獎勵崩潰,還減少了每一步的過度思考,鼓勵跨步驟的長篇推理,從而顯著提升了模型的性能。
然而,訓練過程中也遇到了不少挑戰(zhàn)。特別是在擴展SWE-Bench環(huán)境時,由于需要同時啟動大量Docker容器,一度導致Docker崩潰。為了解決這一問題,研發(fā)人員將Kubernetes支持集成到了R2E-Gym環(huán)境中,實現了容器的高效調度。同時,為每個服務器配備了高性能硬件,并提前下載了所需軟件鏡像,以確保訓練過程的順利進行。
在評估策略方面,DeepSWE采用了“測試時擴展(TTS)”策略,通過多方案生成和智能驗證的方式,將性能推向了新的高度。通過擴展上下文長度和擴展代理部署兩種方法,DeepSWE在SWE-Bench Verified上達到了59%的準確率,實現了新的技術上限。
DeepSWE的成功,離不開其背后的研發(fā)團隊。項目負責人Michael Luo,加州大學伯克利分校電氣工程與計算機科學系博士生,對人工智能和系統(tǒng)領域有著深入的研究。他帶領的團隊,憑借出色的研發(fā)能力和創(chuàng)新精神,成功打造了這款開源軟件工程模型。
DeepSWE的誕生,標志著人工智能編程領域的一次重大突破。它不僅刷新了技術的上限,更為未來的軟件開發(fā)和智能化轉型提供了無限可能。