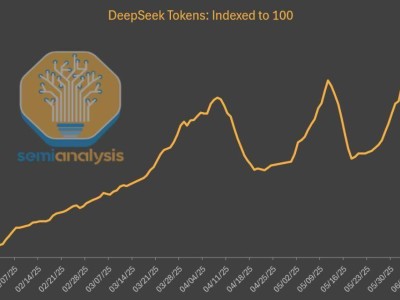
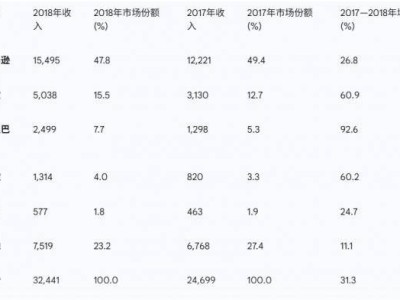
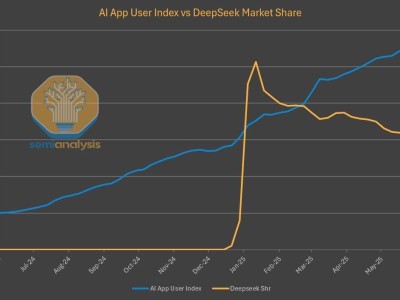
近期,科技界掀起了一場關于大型語言模型相似性的討論。傳聞指出,華為推出的盤古大模型(Pangu Pro MoE)與阿里巴巴達摩院發布的通義千問Qwen-2.5 14B模型在參數結構上存在高度一致性,這一說法迅速在網絡上發酵,并伴隨有相關證據截圖的出現。
據悉,該爭議起源于GitHub項目HonestAGI/LLM-Fingerprint的一項研究。研究團隊對比了多個主流模型后,驚人地發現盤古Pro MoE與Qwen-2.5 14B模型在注意力模塊的設計上存在極高程度的相似性,這在其他模型的對比中未曾出現。這一發現引發了業界對于盤古模型是否基于Qwen模型進行訓練或修改的質疑。
面對這一風波,華為盤古Pro MoE技術開發團隊迅速作出回應,發布了一份官方聲明。聲明中,團隊明確表示,盤古Pro MoE開源模型的部分基礎組件代碼實現確實參考了業界的開源實踐,并涉及其他開源大模型的部分代碼。團隊強調,他們嚴格遵循了開源許可證的要求,在所有開源代碼文件中都清晰標注了版權聲明,這不僅符合開源社區的通行做法,也體現了業界倡導的開源協作精神。
團隊進一步表示,他們始終堅持開放創新的原則,尊重第三方的知識產權,并積極倡導包容、公平、開放、團結和可持續的開源理念。華為方面對全球開發者與合作伙伴的關注和支持表示感謝,并高度重視開源社區的建設性意見。

華為盤古Pro MoE團隊希望通過此次開源,與更多志同道合的伙伴一起,不斷探索并優化模型能力,加速技術的突破與產業落地,共同推動人工智能領域的發展。