德國(guó)知名技術(shù)咨詢公司TNG開(kāi)源了DeepSeek R1的增強(qiáng)版DeepSeek-TNG-R1T2-Chimera。
Chimera是基于DeepSeek的R1-0528、R1和V3-0324三大模型混合開(kāi)發(fā)而成,同時(shí)采用了一種全新的AoE架構(gòu)。這種架構(gòu)在提升性能的同時(shí),還能加快模型的推理效率并節(jié)省token輸出。
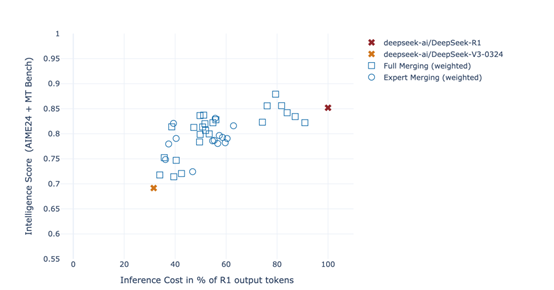
根據(jù)測(cè)試數(shù)據(jù)顯示,Chimera版本的推理效率比R1-0528版本快200%,而推理成本卻大幅度減少。在MTBench、AIME-2024等主流測(cè)試基準(zhǔn)中,Chimera比普通R1性能更好。
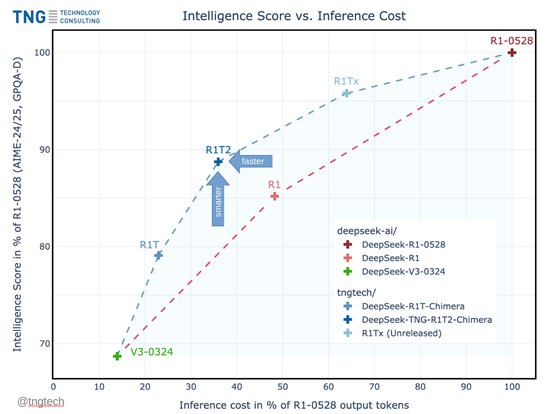
開(kāi)源地址: https://huggingface.co/tngtech/DeepSeek-TNG-R1T2-Chimera
在深入了解AoE架構(gòu)之前,我們先簡(jiǎn)單介紹一下混合專家(MoE)架構(gòu)。MoE架構(gòu)的核心是將Transformer的前饋層劃分為多個(gè)“專家”,每個(gè)輸入標(biāo)記僅路由到這些專家的一個(gè)子集。這種架構(gòu)在效率和性能方面都取得了顯著的成果。
例如,Mistral在2023年發(fā)布的Mixtral-8x7B模型,盡管其在推理過(guò)程中激活的參數(shù)數(shù)量?jī)H為13億,卻與擁有700億參數(shù)的LLaMA-2-70B模型性能相當(dāng),且推理效率提高了6倍。
AoE架構(gòu)的核心則是利用MoE的細(xì)粒度結(jié)構(gòu),通過(guò)線性時(shí)間復(fù)雜度從現(xiàn)有的混合專家父模型中構(gòu)建出具有特定能力的子模型。
通過(guò)插值和選擇性合并父模型的權(quán)重張量,生成新的模型變體,這些變體不僅繼承了父模型的優(yōu)良特性,還能夠根據(jù)需要調(diào)整其行為表現(xiàn)。
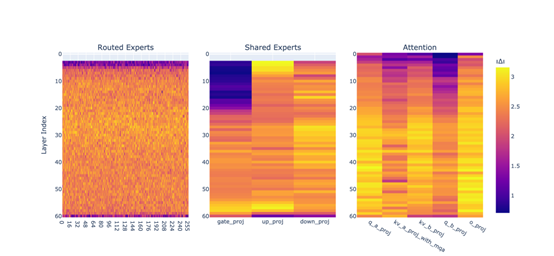
AoE方法的起點(diǎn)是選擇一組具有相同架構(gòu)的模型,這些模型通常是通過(guò)對(duì)一個(gè)預(yù)訓(xùn)練模型進(jìn)行微調(diào)得到的。研究者們選擇了DeepSeek-V3-0324和DeepSeek-R1作為父模型。這兩個(gè)模型都基于DeepSeek-V3架構(gòu),但經(jīng)過(guò)不同的微調(diào),分別在推理能力和指令遵循能力上表現(xiàn)出色。
為了構(gòu)建新的子模型,研究者們首先需要準(zhǔn)備這些父模型的權(quán)重張量。這些權(quán)重張量存儲(chǔ)在模型的權(quán)重文件中,通過(guò)解析這些文件,可以直接訪問(wèn)和操作這些張量。
在準(zhǔn)備好了父模型的權(quán)重張量之后,下一步是進(jìn)行權(quán)重張量的插值與合并。這是AoE方法的核心步驟,通過(guò)這個(gè)步驟,研究者們可以生成具有不同特性的子模型。
研究者們定義了一個(gè)權(quán)重系數(shù)λi,用于控制每個(gè)父模型在合并過(guò)程中的貢獻(xiàn)。在大多數(shù)情況下,這些權(quán)重系數(shù)是凸組合,即滿足λi≥0且所有權(quán)重系數(shù)之和為1。這種設(shè)置允許研究者們?cè)诓煌母改P椭g平滑地插值,生成一系列中間模型。
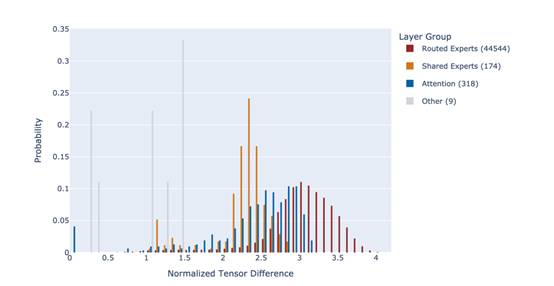
為了進(jìn)一步優(yōu)化合并過(guò)程,研究者們引入了閾值控制和差異篩選機(jī)制。這種方法的核心思想是,只有當(dāng)某個(gè)張量在不同父模型之間存在顯著差異時(shí),才將其納入合并范圍。研究者們定義了一個(gè)閾值δ,只有當(dāng)某個(gè)張量與基礎(chǔ)模型之間的差異超過(guò)該閾值時(shí),才會(huì)將其納入合并范圍。這種方法有效地避免了合并無(wú)關(guān)緊要的差異,從而減少了模型的復(fù)雜度和計(jì)算成本。
在MoE架構(gòu)中,路由專家張量起著至關(guān)重要的作用。這些張量決定了每個(gè)輸入標(biāo)記在推理過(guò)程中被路由到哪些專家模塊。在AoE方法中,研究者們特別關(guān)注了路由專家張量的處理。他們發(fā)現(xiàn),通過(guò)合并不同父模型的路由專家張量,可以顯著提升子模型的推理能力。
因此,在構(gòu)建子模型時(shí),研究者們不僅合并了父模型的權(quán)重張量,還特別關(guān)注了路由專家張量的合并。這種特殊處理使得子模型能夠繼承父模型的推理能力,同時(shí)保持高效的計(jì)算性能。
在確定了要合并的張量和權(quán)重系數(shù)之后,研究者們使用PyTorch框架實(shí)現(xiàn)了模型的合并。通過(guò)迭代訪問(wèn)父模型的權(quán)重文件中的每個(gè)張量對(duì)象,根據(jù)定義的權(quán)重系數(shù)和閾值,計(jì)算合并后的張量值。
這些合并后的張量值被保存到新的權(quán)重文件中,從而生成了新的子模型。這個(gè)過(guò)程不僅高效,而且可以靈活地調(diào)整合并策略,以生成具有不同特性的子模型。