
谷歌DeepMind近期宣布了一項創(chuàng)新成果,推出了一款名為Gemini Robotics On-Device的本地化機器人AI模型。這款模型采用視覺-語言-動作(VLA)架構(gòu),實現(xiàn)了無需云端支持即可直接控制實體機器人的能力。
Gemini Robotics On-Device模型的核心特性顯著。它能夠在機器人設(shè)備上獨立運行,提供低延遲響應(yīng),尤其適用于網(wǎng)絡(luò)不穩(wěn)定的環(huán)境,如醫(yī)療場景。該模型能夠完成高精度的操作任務(wù),如拉開包袋拉鏈、折疊衣物以及系鞋帶,展現(xiàn)了其卓越的操作能力。在硬件適配方面,它支持雙機械臂設(shè)計,并能與ALOHA、Franka FR3及Apollo人形機器人無縫對接。

為了促進開發(fā)者的使用與定制,DeepMind提供了Gemini Robotics SDK工具包。開發(fā)者僅需通過50至100次的任務(wù)演示,便能輕松為機器人添加新功能。該模型還支持MuJoCo物理模擬器測試,為開發(fā)者提供了一個虛擬的測試平臺,降低了實際測試的成本與風險。
在安全保障方面,Gemini Robotics On-Device模型通過Live API實施語義安全檢測,確保機器人動作符合安全規(guī)范。同時,底層安全控制器對動作力度與速度進行精細管理,進一步提升了安全性。DeepMind還開放了語義安全基準測試框架,供開發(fā)者進行更為深入的安全測試。
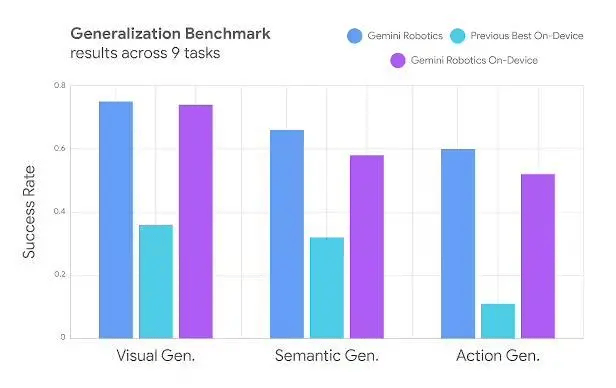
項目負責人Carolina Parada表示,Gemini Robotics On-Device模型借鑒了Gemini多模態(tài)世界理解能力,能夠像Gemini生成文本、代碼、圖像那樣生成機器人動作,為機器人領(lǐng)域帶來了全新的可能。目前,該模型僅面向可信測試計劃的開發(fā)者開放,并基于Gemini 2.0架構(gòu)開發(fā),盡管這一版本略落后于Gemini的最新版本2.5。














