近期,人工智能領域的一項新研究在學術界引起了廣泛討論。亞利桑那州立大學的一組研究人員在預印本平臺arXiv發布了一篇論文,對大型語言模型如ChatGPT的理解提出了新視角。他們質疑,這些被廣泛認為具備思考或推理能力的AI模型,實際上可能只是在執行數據相關性的匹配任務。
論文詳細闡述了研究小組的發現。他們指出,盡管這些AI模型在解答問題時往往會展示出一系列看似邏輯連貫的中間步驟,但這并不等同于真正的推理過程。相反,這些模型更像是在進行大規模的數據相關性計算,而非理解或推斷因果關系。
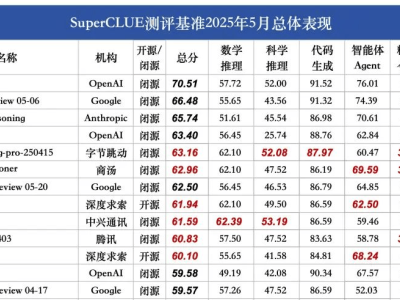
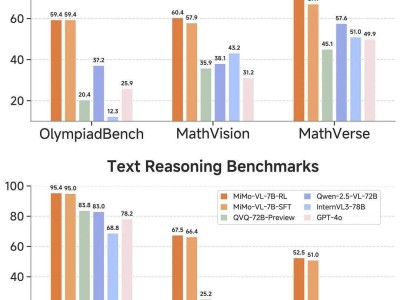
研究小組進一步強調,將AI模型的行為擬人化,可能會誤導公眾對其內在機制的正確理解。他們通過對比一些高性能的推理模型,如DeepSeek R1,來說明這一點。盡管這些模型在某些特定任務上表現出色,但這并不意味著它們具備人類的思考能力。實際上,AI的輸出結果并沒有包含真正的推理步驟。
這一發現對于當前高度依賴AI技術的社會具有重要意義。研究人員提醒,用戶在依賴AI模型進行決策時,應當對其能力保持審慎態度。AI模型生成的中間步驟,盡管看似合理,但可能并不反映真正的推理過程,這可能會導致用戶對AI的問題解決能力產生過度樂觀的誤判。