近日,備受矚目的SuperCLUE發布了其最新的《中文大模型基準測評報告》,該報告針對2025年5月的中文大模型能力進行了全面評估。
在本次測評中,有兩款模型尤為突出,它們分別是豆包1.5深度思考模型(Doubao-1.5-thinking-pro)和商湯科技的日日新V6多模態模型(SenseNova-V6 Reasoner)。這兩款模型憑借其卓越的表現,成功超越了之前的領先者Gemini 2.5 Flash Preview,成為當前中文大模型領域的佼佼者。
緊隨其后的第二梯隊模型同樣不容小覷,包括DeepSeek-R1、NebulaCoder-V6、Hunyuan-T1和DeepSeek-V3。這些模型在各自的領域內均有著出色的表現,并在本次測評中展現出了強大的競爭力。
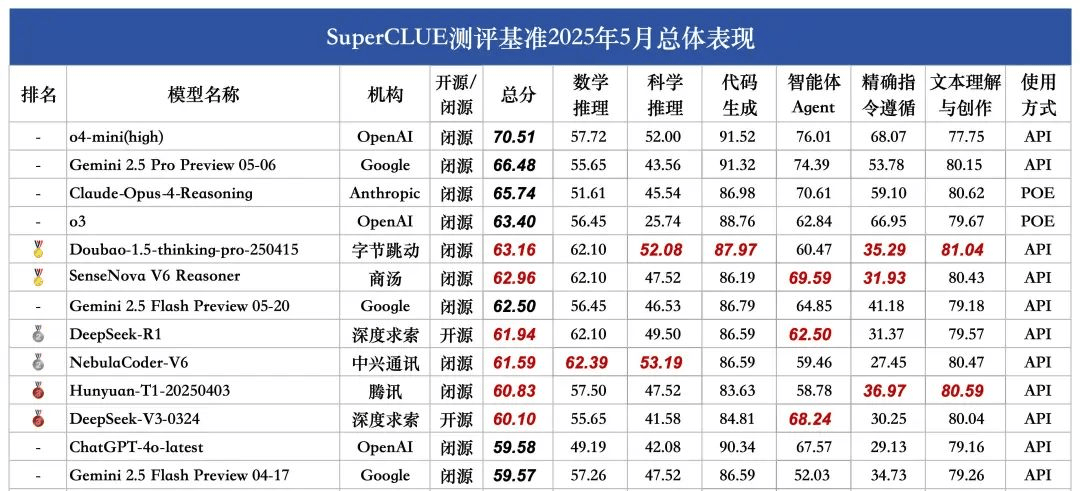
據SuperCLUE報告指出,當前國內外中文大模型在通用能力方面的差距正在逐漸縮小。在國內市場中,Doubao-1.5-thinking-pro-205415和SenseNova V6 Reasoner憑借其出色的表現,成功吸引了業界的廣泛關注。這兩款模型的出色表現,也預示著國內推理模型市場的競爭格局正在逐步形成。
SuperCLUE作為行業權威的通用大模型綜合性測評基準,其本次測評覆蓋了數學推理、科學推理、代碼生成、智能體Agent、精確指令遵循以及文本理解與創作六大任務。測評題目總量達到了1579道多輪簡答題,旨在全面評估大模型在中文環境下的通用能力。
通過本次測評,我們可以清晰地看到當前中文大模型領域的競爭格局以及各模型的優劣所在。這不僅為行業內的研發者提供了寶貴的參考信息,也為廣大用戶提供了更加準確的選擇依據。