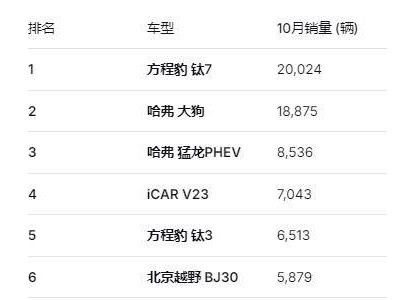
在近期舉辦的科大訊飛1024開發者節上,一項AI軟硬一體解決方案成為全場焦點。該方案通過深度融合AI算法與硬件架構,成功攻克了復雜環境下的語音識別難題,尤其在強噪聲、遠距離場景中展現出卓越的精準識別與理解能力,標志著語音與視覺智能融合技術邁入新階段。
傳統語音識別系統在嘈雜環境中常面臨準確率驟降的困境,而科大訊飛此次推出的解決方案通過系統性創新,實現了從“聽清”到“看懂”的跨越。其核心在于將語音增強、聲源定位、回聲消除等算法與硬件架構深度結合,形成軟硬協同的感知體系,顯著提升了復雜場景下的信息處理能力。
基于這一技術底座,科大訊飛多款硬件產品性能實現質的飛躍。其中,智能辦公本X5搭載行業首創的“上4下4環”八麥克風陣列,在遠場高噪聲環境下,其語音識別效果遠超同期旗艦手機iPhone17Pro;AI翻譯耳機在地鐵、展會等動態嘈雜場景中,識別準確率高達97.1%;雙屏翻譯機2.0更是在90分貝的工業噪音環境中,仍保持98.69%的語音識別準確率,刷新了行業紀錄。
技術突破的背后,是科大訊飛在多模態感知算法領域的長期積累。通過持續優化語音增強技術、提升聲源定位精度、強化回聲消除效果,并結合視覺信息的輔助感知,系統得以在復雜環境中精準捕捉目標聲音,同時過濾無效干擾,為硬件產品提供了強大的技術支撐。
開發者節上,另一項引發熱議的技術是“百變聲音復刻”。基于星火語音大模型,該技術僅需用戶提供一句錄音,即可高保真復刻任意音色,并支持通過指令快速生成不同風格的聲音輸出。這一創新使得個性化語音創作門檻大幅降低,用戶無需專業設備或技能,即可輕松打造專屬“AI聲音分身”。
目前,該技術已具備廣泛的應用潛力。在數字人領域,可實現高度擬人化的語音交互;在有聲讀物和影視配音行業,能快速生成多樣化聲線,滿足創作需求;在內容創作場景中,更可為創作者提供便捷的語音定制工具,推動個性化表達方式的革新。