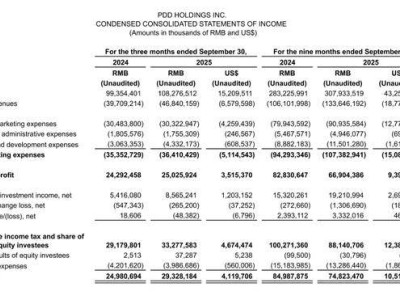
在全球半導體產業競相追逐算力極限、人工智能大模型對計算資源需求持續攀升的背景下,北京大學科研團隊憑借一項突破性成果,為全球計算領域注入新的活力——他們成功研發出一款基于阻變存儲器的新型模擬矩陣計算芯片,標志著中國在高端算力自主化道路上邁出關鍵一步。
這項由北京大學人工智能研究院孫仲研究員團隊與集成電路學院聯合完成的研究,近日以論文形式發表于國際權威期刊《Nature·Electronics》。論文提出的“模擬計算”范式,顛覆了傳統數字計算依賴二進制“0”與“1”的底層邏輯,轉而通過電壓和電流的連續變化直接完成復雜運算,為解決馮·諾依曼架構“存儲墻”問題提供了全新思路。
傳統數字芯片的計算過程,本質上是無數次“0變1、1變0”的開關操作。數據需在存儲器與處理器間頻繁搬運,如同狹窄管道中的洪流,既消耗時間又浪費能量。而北大團隊研發的模擬芯片,則讓計算回歸“本質”——數學中的“10”不再被拆解為二進制序列,而是直接表現為十伏的電流或流動的能量。這種“存算一體”的設計,使芯片在硬件層面實現了計算與存儲的深度融合,徹底擺脫了“內存墻”的束縛。
實驗室數據顯示,該芯片在16×16矩陣的24位定點求逆任務中,相對誤差僅10??,精度達到行業領先水平。更令人驚嘆的是其效率:完成相同計算量,頂級GPU需運行一整天,而這款模擬芯片僅需一分鐘,能效比提升100倍,且幾乎不產生熱量。這意味著,未來訓練AI大模型時,原本需要數百張GPU組成的算力農場,可能被一顆巴掌大小的模擬芯片替代。
技術的突破不僅在于“快”,更在于“巧”。研究團隊創新性地將“低精度模擬求逆”與“高精度模擬矩陣-向量乘法”結合:前者通過快速逼近提供初始解,后者利用精確修正確保最終精度,二者協同實現24位定點計算。配合塊矩陣協同算法,多個芯片可并行求解更大規模矩陣,展現了“新型信息器件+原創電路+經典算法”的協同設計之美。
在硬件實現上,芯片采用40nm CMOS工藝,阻變存儲器陣列支持3比特電導態編程。這種設計使計算與存儲在物理層面合二為一,如同讓思維與記憶回歸同一腦區,使芯片能夠“理解數據”而非簡單“處理數據”。
實際應用中,這款芯片的表現同樣驚艷。在大規模多輸入多輸出(MIMO)信號檢測任務中,僅需三次迭代即可使接收圖像與原始圖像高度一致,誤碼率-信噪比曲線接近32位浮點GPU水平。這不僅為無線通信信號處理提供了加速方案,更可能成為AI訓練中“二階優化”的硬件基石,大幅降低模型訓練成本。
對于邊緣計算領域而言,這款芯片的低功耗、高精度特性更具革命性意義。未來,機器人、無人機、智能終端等設備將無需依賴云端,即可在本地完成AI模型的訓練與推理,真正實現“端側智能”。當AI能夠直接在設備上學習、思考并決策,一個“萬物智能”的時代將悄然來臨。
孫仲研究員表示:“我們的目標不是取代GPU,而是與它形成互補,讓計算更高效、更智慧。”這句話背后,既體現了科研工作者的務實態度,也彰顯了中國在算力領域從追趕者到開辟者的自信。當電流開始“思考”,當“存算一體”成為現實,中國科學家正用創新與堅持,重新定義計算的邊界。