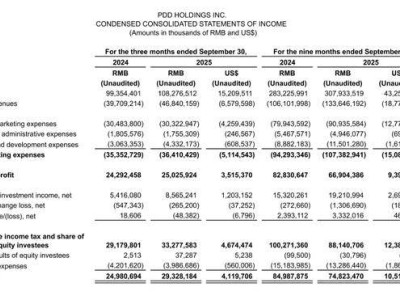
英偉達(dá)科研團(tuán)隊(duì)近日宣布推出全新全模態(tài)理解模型OmniVinci,該成果在多模態(tài)基準(zhǔn)測試中展現(xiàn)顯著優(yōu)勢,較當(dāng)前最優(yōu)模型得分提升19.05個百分點(diǎn)。值得關(guān)注的是,這一突破性成果僅使用六分之一的訓(xùn)練數(shù)據(jù)量,在數(shù)據(jù)利用效率方面形成代際優(yōu)勢。
研究團(tuán)隊(duì)構(gòu)建了多感官融合的統(tǒng)一潛在空間架構(gòu),通過創(chuàng)新性數(shù)據(jù)管理策略實(shí)現(xiàn)視覺、聽覺與文本信息的深度交互。這種跨模態(tài)理解機(jī)制使AI系統(tǒng)能夠模擬人類感知模式,對復(fù)雜場景進(jìn)行多維度解析。在Dailyomni基準(zhǔn)測試中,該模型在音頻理解MMAR子項(xiàng)和視覺Video-MME子項(xiàng)分別超出Qwen2.5-Omni模型1.7分和3.9分,而訓(xùn)練數(shù)據(jù)量僅為后者的六分之一。
核心技術(shù)突破體現(xiàn)在三大創(chuàng)新模塊:OmniAlignNet通過挖掘視聽信號的互補(bǔ)特性強(qiáng)化特征對齊;時間嵌入分組技術(shù)(TEG)建立時序信息編碼框架;約束旋轉(zhuǎn)時間嵌入(CRTE)解決絕對時間定位難題。這些技術(shù)共同構(gòu)成全模態(tài)對齊機(jī)制,確保模型在動態(tài)場景中保持精準(zhǔn)的時間感知能力。
訓(xùn)練方法采用階段性強(qiáng)化策略,初期進(jìn)行模態(tài)專項(xiàng)訓(xùn)練夯實(shí)基礎(chǔ)能力,后期實(shí)施全模態(tài)聯(lián)合訓(xùn)練提升綜合理解水平。研究團(tuán)隊(duì)利用現(xiàn)有視頻問答數(shù)據(jù)集開發(fā)隱式學(xué)習(xí)框架,有效提升音視頻聯(lián)合解析的準(zhǔn)確度。這種漸進(jìn)式訓(xùn)練模式使模型在保持高效的同時,實(shí)現(xiàn)跨模態(tài)知識的有機(jī)融合。
該成果的開源發(fā)布將為全球AI社區(qū)提供重要技術(shù)資源,其高效的數(shù)據(jù)利用模式和創(chuàng)新的架構(gòu)設(shè)計,有望推動智能系統(tǒng)在多媒體處理、人機(jī)交互等領(lǐng)域的實(shí)質(zhì)性進(jìn)展。研究團(tuán)隊(duì)透露,后續(xù)將深化多模態(tài)預(yù)訓(xùn)練框架的研究,探索更高效的跨模態(tài)知識遷移方法。