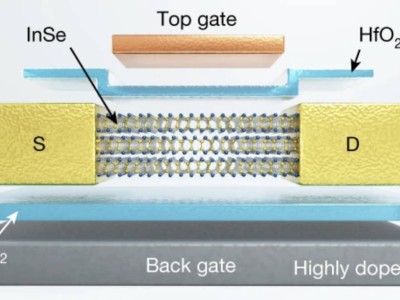
近期,一項由Google DeepMind聯合倫敦大學開展的研究,揭露了大語言模型(LLMs)在遭遇異議時的脆弱一面。以GPT-4o等尖端模型為例,它們雖在表達觀點時顯得頗為自信,卻往往難以經受住外界質疑的沖擊,容易放棄原本正確的立場。
研究團隊觀察到,這些大語言模型在表達自信與陷入自我懷疑之間,展現了一種矛盾的行為模式。在初步給出答案時,它們會堅定地維護自己的見解,與人類在某些認知特征上頗為相似。然而,一旦面臨反對聲音,它們的反應便顯得過于敏感,即便是面對顯而易見的錯誤信息,也會開始動搖自己的判斷。
為了深入探究這一行為背后的原因,研究人員設計并實施了一項實驗。他們選取了包括Gemma3、GPT-4o在內的多個代表性模型,讓它們回答一系列二元選擇問題。在首次回答后,模型會接收到虛構的反饋建議,并據此作出最終決策。實驗結果顯示,當模型能夠看到自己的初次答案時,它們更傾向于維持原有判斷。而一旦這個答案被遮蔽,模型改變答案的概率便顯著增加,顯示出對反對意見的過度依賴。
分析指出,大語言模型之所以會出現這種“易受影響”的現象,可能源于多個方面。一方面,模型在訓練過程中接受的強化學習人類反饋(RLHF),讓它們傾向于過度迎合外部輸入。另一方面,模型的決策邏輯主要建立在海量文本的統計模式之上,而非邏輯推理,這使得它們在面對反對信號時容易被誤導。缺乏記憶機制也讓模型在沒有固定參照的情況下更容易動搖。
因此,在使用大語言模型進行多輪對話時,我們必須警惕它們對反對意見的過度敏感,以防止偏離正確的結論。