近期,一項針對大型語言模型(LLM)的研究揭示了一個驚人的發現:當輸入文本的長度擴展到1萬個tokens時,多個主流大模型的性能出現了顯著下滑,宛如“智商”驟降。這一現象并非均勻發生,而是在某些特定節點上,模型的準確率出現了斷崖式下跌。
以Claude Sonnet 4為例,在處理1000個tokens后,其準確率從90%一路下滑至60%。而GPT-4.1和Gemini 2.5 Flash則表現出先下降后放緩再下降的趨勢。當上下文長度達到1萬個tokens時,這些模型的準確率普遍降至50%左右。

這意味著,大模型在閱讀同一本書的不同頁面時,其“智商”可能會截然不同。更令人驚訝的是,不同大模型在“閱讀這本書”的過程中,出現性能驟降的頁面也各不相同。例如,GPT-4.1可能在讀到第10頁時就已“失智”,而Claude或許能堅持到第100頁。
這項研究由Chroma團隊完成,他們利用升級版的“大海撈針”(NIAH)測試方法,對包括GPT-4.1、Claude 4、Gemini 2.5和Qwen3等在內的18個主流大模型進行了測試。測試結果顯示,隨著輸入長度的增加,模型的性能呈現出越來越差的趨勢。
研究還首次系統性地揭示了輸入長度對模型性能的非均勻影響。實驗表明,不同模型的性能可能在某一特定的tokens長度上,準確率發生驟降。這一發現得到了網友的廣泛認可,因為以往人們雖然遇到過輸入長度增加時大模型性能不佳的情況,但并未有人深入探究過這個問題。
為了更深入地了解輸入長度對模型性能的影響,研究人員設計了四項對照實驗。這些實驗基于保持任務復雜度不變,僅改變輸入長度的核心原則,旨在探究語義關聯性、干擾信息、文本結構等因素對模型性能的影響。
實驗結果顯示,輸入長度是性能衰減的核心變量。無論任務簡單與否,模型在處理長文本時的可靠性都會下降。語義關聯性、干擾信息和文本結構等因素會進一步加劇模型的性能衰減。例如,在針-問題相似度實驗中,低相似度組的模型性能衰減更為顯著;在干擾信息實驗中,即使單一干擾項也會導致模型性能低于基線,而多重干擾項會進一步加劇性能衰減。
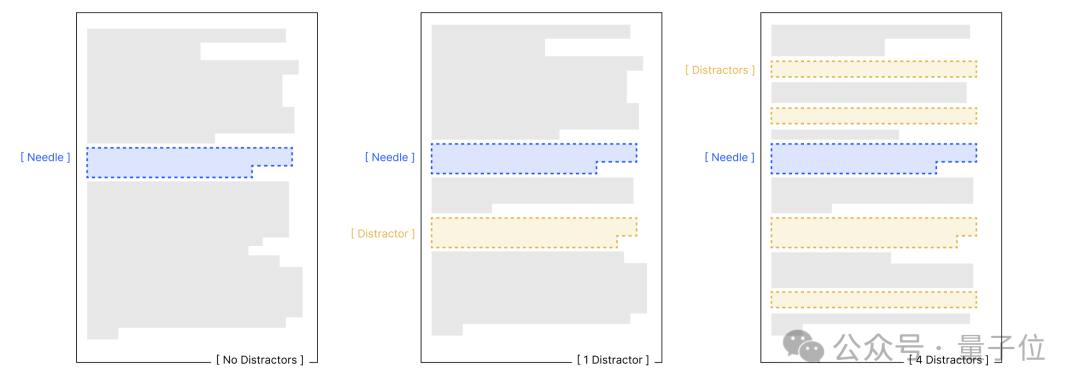
不同模型對這些因素的敏感程度也存在差異。例如,Claude系列模型在不確定時傾向于棄權,表現出較低的幻覺率;而GPT系列模型則更可能生成自信但錯誤的答案,受干擾影響更明顯。Gemini和Qwen模型的表現則波動較大,易受干擾項數量和輸入長度的雙重影響。
這項研究不僅揭示了大型語言模型在處理長文本時的局限性,也為未來的研究提供了新的方向。研究人員建議,在構建LLM應用時,應給出明確、清晰的指令,并在收集到足夠的信息后保存上下文,以添加一個檢查點來提高模型的穩定性和可靠性。
Chroma團隊不僅致力于LLM長上下文處理領域的研究,還開發了一個開源的AI應用數據庫——Chroma。該數據庫旨在通過將知識和技能整合為大語言模型可調用的模塊,簡化LLM應用的構建過程。目前,Chroma計劃推出免費的技術預覽,并表示將100%專注于構建有價值的開源軟件。