「造芯」不易,「用芯」更難。
大模型加速落地,國產(chǎn)芯片需求日盛,但模型真正能在國產(chǎn)芯上「開箱即用」者寥寥無幾——這關(guān)鍵的「最后一公里」,誰來鋪路?
現(xiàn)在,有個社區(qū)牽頭 「組隊攻堅」 ,給出了一種解法。
6 月 30 日,百度文心大模型 4.5 系列正式開源,并同步登陸 AI 開源社區(qū)——魔樂社區(qū)( Modelers.cn )。
趁熱打鐵,魔樂社區(qū)同步正式發(fā)起「模型推理適配協(xié)作計劃」(以下簡稱「適配計劃」),集結(jié)開發(fā)者、算法團隊、芯片廠商與推理工具伙伴,共建開源協(xié)同生態(tài)。
目標(biāo)只有一個:讓大模型跑遍中國芯。
開源模型如何跑遍中國芯?
先拆解一下「適配」這件事到底在適配什么。
一個大模型順利實現(xiàn)推理應(yīng)用落地,要跨越三道檻兒:
適配推理引擎:先讓引擎「讀懂」模型,能解釋其結(jié)構(gòu)、識別其算子;
適配計算平臺:讓芯片「聽得懂」引擎分發(fā)的任務(wù),高效完成各類操作;
適配上層調(diào)度:讓模型能被業(yè)務(wù)系統(tǒng)便捷接入調(diào)用,真正上線服務(wù)。
當(dāng)前,業(yè)界已發(fā)展出多樣化的工具來支持大模型推理和適配的各個環(huán)節(jié)。
比如,vLLM 等高性能推理引擎,CANN、MUSA 等計算架構(gòu),F(xiàn)astDeploy、FlagServing 等部署工具,以及眾多開源的模型轉(zhuǎn)換、量化、融合工具等……這些工具在各自領(lǐng)域都發(fā)揮了重要作用,整個工具鏈其實已經(jīng)相對完整。然而,挑戰(zhàn)在于如何有效連接和協(xié)同這些分散的工具鏈與適配經(jīng)驗。因此,亟需一個跨環(huán)節(jié)的協(xié)作平臺與機制,把這些資源組織起來,解決「最后一公里」的適配難題。
于是,魔樂社區(qū)推出「模型推理適配協(xié)作計劃」,并動手做了幾件事。
第一件事,是把原來的「鏡像中心」升級為「工具中心」,位置也從「更多」菜單一躍來到首頁 C 位,對標(biāo)模型庫、數(shù)據(jù)集 ——
這一調(diào)整絕非簡單的位置遷移,而是將開放的工具鏈提升至與模型、數(shù)據(jù)同等重要的生態(tài)基座地位。
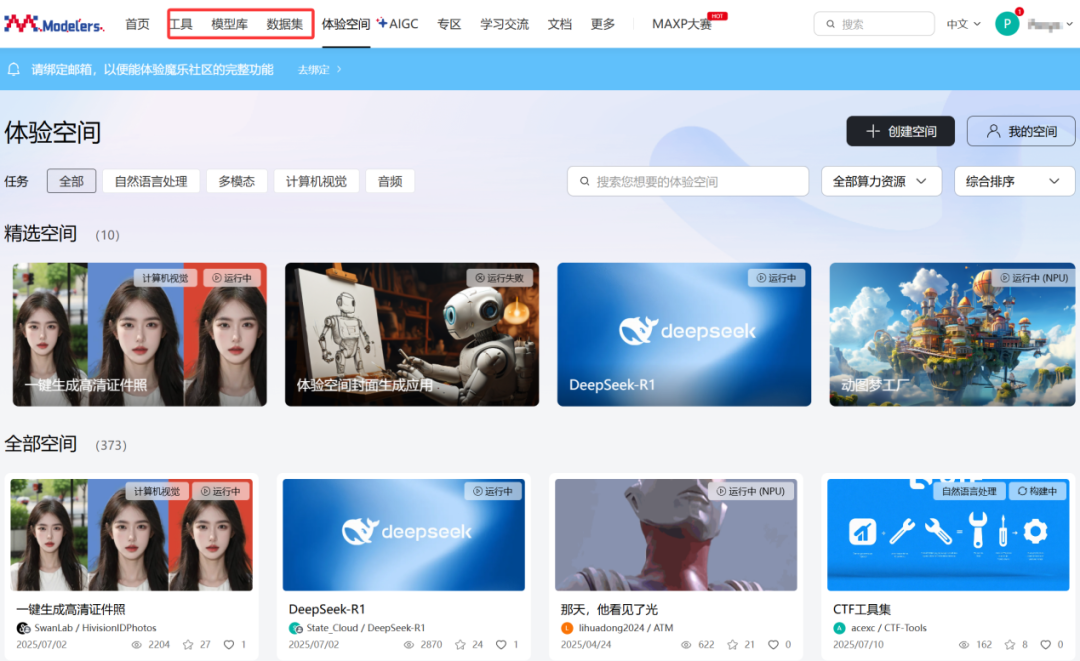
現(xiàn)在,開發(fā)和部署工具,與模型庫、數(shù)據(jù)集并列首頁「C位」。
類似模型庫的運作邏輯,「工具」中心將提供模型轉(zhuǎn)換遷移工具,也將支持開發(fā)者上傳自己適配好的推理鏡像、工具鏈和運行環(huán)境,還可以對已有鏡像進行更新。
每次發(fā)布需社區(qū)審核,確保質(zhì)量穩(wěn)定、可復(fù)用。
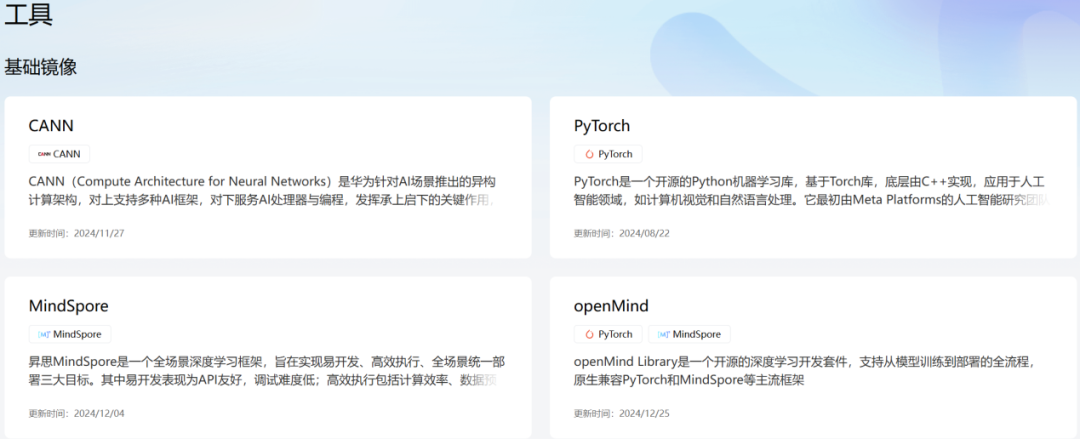
與此同時,「工具」依舊保留了代碼托管能力,方便開發(fā)者在魔樂生態(tài)內(nèi)實現(xiàn)適配共享。
換句話說,升級后的板塊就是想讓「環(huán)境跟著模型走」,將碎片化的適配經(jīng)驗沉淀為標(biāo)準(zhǔn)化、可復(fù)用的結(jié)構(gòu)化基礎(chǔ)設(shè)施,讓后續(xù)開發(fā)者無需重復(fù)造輪子,直接站在已有成果上推進適配和性能優(yōu)化,大幅降低協(xié)作成本。
另一件事,是把托管板塊升級為協(xié)作空間。
以前,模型架構(gòu)和權(quán)重文件一經(jīng)上傳,基本就「塵埃落定」。但像 Readme 文檔、適配好的推理代碼等內(nèi)容,卻得隨著芯片、工具鏈適配進展不斷更新。
比如,今天模型適配了一個芯片,明天又支持了另一種,這些信息和代碼都得有人來更新和上傳,并且不同開發(fā)者的適配成果可能分散在各處,難以匯總復(fù)用。
現(xiàn)在,在「協(xié)作空間」——
所有用戶均可提交 PR(代碼合并請求),共同參與文檔撰寫、適配代碼開發(fā)與推理配置優(yōu)化。
文檔即代碼:Readme 不再是靜態(tài)說明,而是支持多人實時編輯的協(xié)作載體,適配進展、使用指南等信息實時同步。
比如,模型開發(fā)者上傳了一個大模型到魔樂社區(qū),不止模型權(quán)重,還有配套的推理工具鏈。一旦模型被標(biāo)記為「基礎(chǔ)模型」, 模型卡片就會自動開啟「協(xié)作」入口。
這時候,開發(fā)者可針對不同芯片上傳獨立的適配代碼分支,形成版本清晰的 「芯片適配庫」。
例如,如果有工程師想將模型適配跑在某款芯片上(例如昇騰),只需要點開「協(xié)作」按鈕,選擇目標(biāo)推理引擎,新建一個「Ascend」文件夾,提交適配后的推理代碼,提個 PR,就能提交到社區(qū)。
社區(qū)會有審核機制,一旦驗證通過,就能被正式合入模型項目中,成為社區(qū)認可的適配版本。
每一個適配版本,就是一個獨立的子工程,版本分明,職責(zé)清晰,協(xié)作記錄也都有跡可循。
除代碼外,適配過程中產(chǎn)生的量化權(quán)重、優(yōu)化配置等資產(chǎn)也可通過 PR 提交,形成完整的技術(shù)方案。
這種機制將分散的適配工作聚合到統(tǒng)一平臺,支持一鍵下載與二次開發(fā), 避免了成果碎片化,讓每一次適配進展都能沉淀為社區(qū)共享的資產(chǎn)。
為了讓「適配計劃」真正跑起來,魔樂社區(qū)廣泛聯(lián)動產(chǎn)業(yè)力量。
一方面聯(lián)動壁仞科技、海光、華為(昇騰)、摩爾線程、沐曦、算能、燧原科技等國產(chǎn)算力廠商(按中文首字母排序,無先后順序),為開發(fā)者提供硬件、工具和技術(shù)支持。
另一方面,整合多元化適配和推理軟件生態(tài),并聯(lián)合工具伙伴,助力開發(fā)者快速掌握適配工具鏈,實現(xiàn)跨硬件平臺與引擎組合的深度推理性能調(diào)優(yōu)。
與此同時,還牽手伙伴共建教程、補文檔、傳經(jīng)驗,手把手幫開發(fā)者跑通流程、填平坑點。
接下來,「適配計劃」 將持續(xù)開放,持續(xù)吸納更多芯片廠商、模型開發(fā)者與開發(fā)者加入;SIG(特別興趣小組)技術(shù)組也將進入常態(tài)化運作,聚焦適配技術(shù)攻堅與標(biāo)準(zhǔn)制定。
若此協(xié)作機制成功運轉(zhuǎn),將有望解決國產(chǎn)芯片生態(tài)最棘手的 「協(xié)同短板」—— 讓模型與芯片的適配從 「零散突破」 走向 「體系化落地」,為國產(chǎn) AI 算力生態(tài)的閉環(huán)構(gòu)建提供關(guān)鍵支撐。
「適配計劃」背后
很多人還記得,DeepSeek-R1 爆火出圈后,一件不太常見的事發(fā)生了:國產(chǎn)芯片廠商「組團發(fā)聲」,紛紛宣布已完成對該模型的適配,并表示正在推進更多大模型的適配工作。
國產(chǎn)模型火了,國產(chǎn)算力也想借勢出圈。背后的邏輯其實很直接——
只有模型真能在國產(chǎn)芯片上穩(wěn)定跑起來,芯片才有機會真正用起來。
但現(xiàn)實卻很尷尬:大模型加速落地,隨著金融、政務(wù)、制造等重點行業(yè)對「自主可控」的需求越來越強,國產(chǎn)芯片的出場機會越來越多,然而,真正能做到「即拿即用」的大模型,依舊寥寥無幾。
為什么會這樣?
首先,這和開源模型本身的特點有關(guān)。
開源大模型不是一個「裝好就能跑」的整包,它往往拆成模型架構(gòu)、權(quán)重和推理代碼三塊。HuggingFace這樣的開源平臺聚焦模型分發(fā)和訓(xùn)練等,并不側(cè)重構(gòu)建異構(gòu)算力的協(xié)同適配機制。
其次,是技術(shù)層面的現(xiàn)實難題。
國產(chǎn)芯片之間架構(gòu)差異大,很多都有自己獨立的推理引擎。同一個模型,想讓它在不同芯片上跑得通、跑得快,就得「量身定制」——專門做適配、調(diào)度、優(yōu)化。
比如,有的芯片需要做量化來壓縮模型體積,有的要進行算子融合來提速。
現(xiàn)在,這些活兒是誰在做?
一部分由模型廠商親自下場,但資源有限,很少有團隊會專門為不同國產(chǎn)芯片配專屬工程師。
更多時候,是芯片廠商主動出擊。隨著大模型推理結(jié)構(gòu)的日趨標(biāo)準(zhǔn)化、算子體系逐步統(tǒng)一,「自己動手」的門檻已顯著降低。就像 DeepSeek 爆火之后,一些廠商為了盡快跑通,從芯片指令集到內(nèi)存管理、數(shù)據(jù)傳輸都做了大幅調(diào)整。
還有一類,就是開發(fā)者出于興趣或業(yè)務(wù)需求自發(fā)適配。但這類工作高度分散、重復(fù)投入嚴(yán)重,質(zhì)量也參差不齊。
對比之下,為什么 Hugging Face 上的模型大多都能在英偉達 GPU 上開箱即用?靠的不是單一廠商的「單點突破」,而是整個生態(tài)高度打通,工具鏈成熟完善。
這也是魔樂社區(qū)「適配計劃」要解決的核心問題——
不再單打獨斗,通過構(gòu)建統(tǒng)一的協(xié)作框架,串聯(lián)模型開發(fā)者、芯片方、工具方與開發(fā)者,形成生態(tài)合力,一起把模型從「能發(fā)布」推到「即插即用」。
魔樂:AI 開源的「中國樣本」
為什么是魔樂來牽頭做這件事?
答案要從它的「出身」和「使命」說起。
2024年 8 月,在央企巨頭、中國電信天翼云的牽頭下,魔樂社區(qū)正式上線。與很多主打「模型集市」的開源平臺不同,魔樂從一開始就瞄準(zhǔn)了另一個更現(xiàn)實、也更棘手的問題:
開源 AI 發(fā)展,要的不只是「代碼開放」,還得「能協(xié)同、能落地」。
模型當(dāng)然重要,但真正推動國產(chǎn) AI 落地的,不只是一個個模型,而是支撐它們生長的底座系統(tǒng)——包括開源數(shù)據(jù)集、適配工具、部署引擎,乃至合規(guī)、調(diào)度、治理等基礎(chǔ)能力。
因此,魔樂選擇做一個中立、公益的開源社區(qū),扮演「國產(chǎn) AI 落地的基礎(chǔ)設(shè)施」。
他們從零搭出一套覆蓋模型、數(shù)據(jù)、工具、應(yīng)用與算力五大板塊的開源協(xié)作體系。
社區(qū)已匯聚 1000+ 優(yōu)質(zhì)大模型、涵蓋 TeleChat、DeepSeek、Qwen、智譜等大模型,其中多數(shù)都已經(jīng)適配好國產(chǎn)算力。
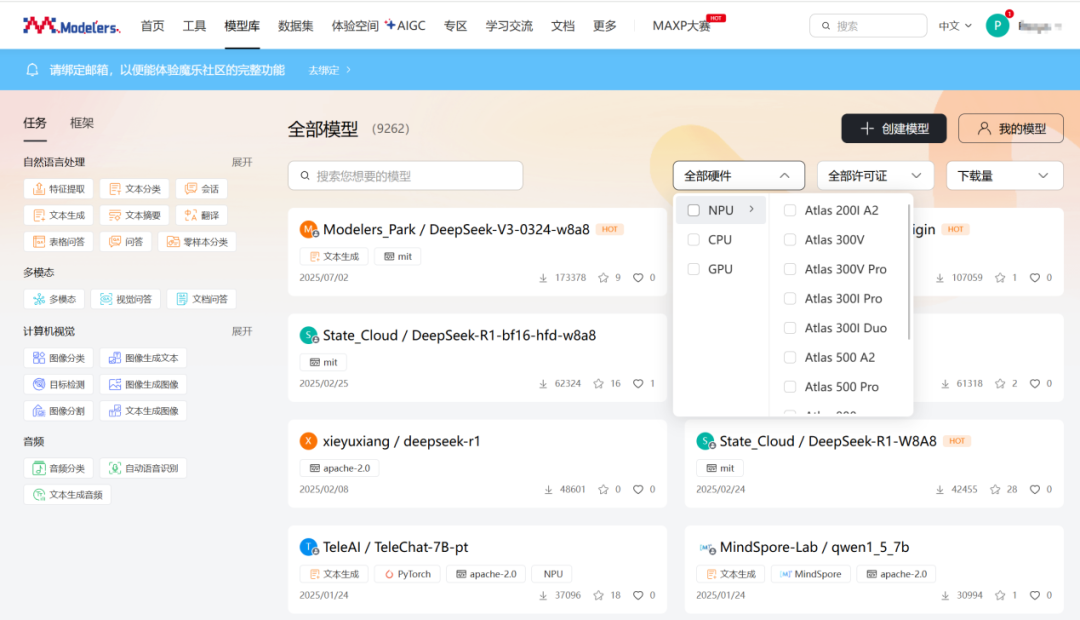
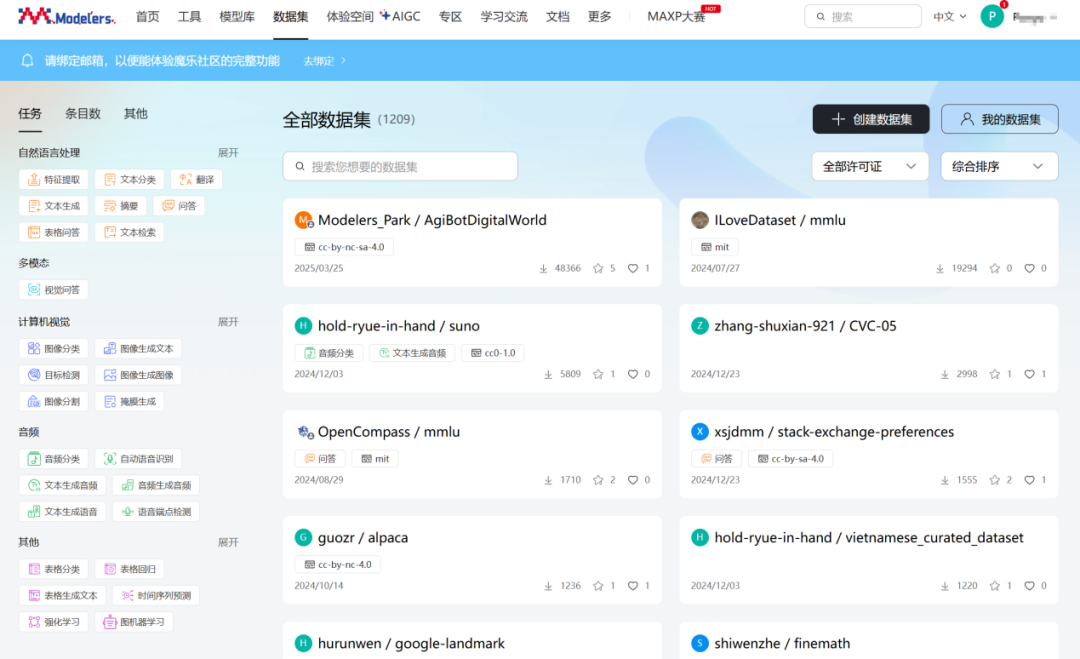
依托天翼云及「算力朋友圈」供給,社區(qū)可提供公益性國產(chǎn)化算力資源。
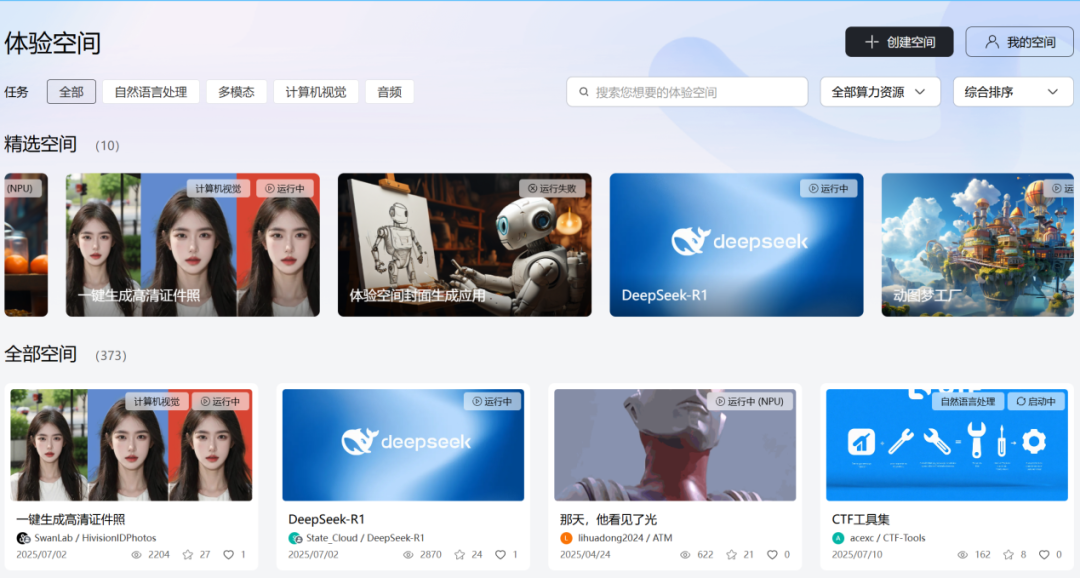
最直觀的體現(xiàn)就是魔樂推出的「在線體驗空間」:
基于社區(qū)提供的模型和算力,開發(fā)者可通過 Gradio 等主流 SDK 快速搭建 AI 應(yīng)用,并一鍵部署、分享。
還有線上、線下的學(xué)習(xí)交流活動。
魔樂社區(qū)不只有在線平臺,最近還正式成立了理事會,進一步規(guī)范社區(qū)管理與生態(tài)共建。
「中國樣本」,步步為營
不到一年時間,魔樂就搭起了生態(tài)的基本盤——
已聚合超過 20 家深度合作伙伴,托管模型、數(shù)據(jù)、工具等各類開源項目累計突破 1 萬個;
首發(fā)多個昇騰適配大模型,推動模型實現(xiàn)國產(chǎn)化原生適配;
模型、數(shù)據(jù)與工具融合共建,已上線 200 多個國產(chǎn)化 AI 應(yīng)用。
更重要的是,這套生態(tài)始終圍繞「產(chǎn)學(xué)研協(xié)同」展開,AI 落地的挑戰(zhàn)正在被「共建、共享」的生態(tài)范式一點點瓦解。
魔樂社區(qū)致力于發(fā)掘、打造和推廣好的項目。一方面,深耕高校等原生創(chuàng)新場景,定向發(fā)掘一批基于國產(chǎn)算力起步的潛力項目。
另一方面,通過「國產(chǎn)算力應(yīng)用創(chuàng)新大賽」等機制,實戰(zhàn)中篩選優(yōu)質(zhì)標(biāo)的,推動它們與底層算力平臺的深度適配與融合。
找到好項目只是起點,更關(guān)鍵的是——放大價值。
魔樂為項目提供從算力資源、工具鏈到調(diào)度框架、落地渠道的全棧支持,推動它們從 demo 走向產(chǎn)品、從實驗室走向產(chǎn)業(yè)化,讓每一個「跑得通」的應(yīng)用都有「火出圈」的可能。
例如 Stable Diffusion WebUI、ComfyUI 雖在設(shè)計創(chuàng)作領(lǐng)域早已成名,但缺乏系統(tǒng)的國產(chǎn)適配支持。魔樂正加大力度,推動它們與國產(chǎn)工具鏈深度融合,加速落地,近期正式上線了 AIGC 專區(qū),已實現(xiàn)基于國產(chǎn)算力的快速專業(yè)生圖。
如今,全國已有多個有影響力的 AI 開源社區(qū),都在不斷推進國產(chǎn) AI 能力的積累。
但這只是開始。
隨著大模型快速普及、國產(chǎn)軟硬件協(xié)同需求走強,AI 社區(qū)或?qū)⒂瓉碚嬲摹妇畤姇r刻」。
而魔樂選擇了一條更難、但也更有價值的路——不止做模型的「集市」,更要做模型、算力、工具的協(xié)作平臺。
堅持中立、公益、開放的定位,魔樂正推動大模型在「中國芯」上真正跑起來,成為國產(chǎn)AI算力生態(tài)自主可控與高效協(xié)同的重要支撐。