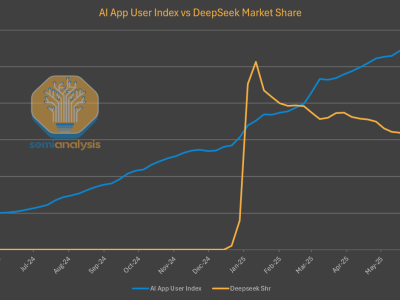
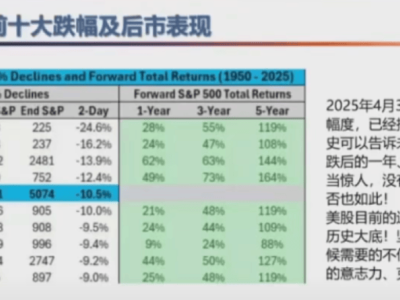
在AI領域的探索之旅中,一場關于大模型架構的新革命正悄然醞釀。近日,一份深度報告揭示了這一領域的最新動向,探討了誰將成為下一代架構的領軍者。
自Transformer架構橫空出世以來,AI界對其路徑依賴的爭議便不絕于耳。面對這一現狀,行業對架構創新的渴求愈發迫切。目前,業界主要有兩大探索方向:一是對Transformer進行改良,通過稀疏Attention等技術,提升計算效率和內存利用率;二是開辟非Transformer架構的新天地,擺脫對Attention機制的依賴,在長序列建模等方面展現獨特優勢,且這些創新架構往往呈現出融合的特點。
回顧大模型架構的發展歷程,從深度學習初入NLP領域,到Transformer時代的開啟,預訓練與Scaling Law范式主導一切,再到Transformer時代達到巔峰,基礎模型參數規模屢創新高,每一步都見證了AI的飛速進步。然而,時至今日,預訓練范式已漸顯疲態,創新架構的探索熱潮正在興起。
Transformer架構雖強,但并非無懈可擊。其二次計算復雜度導致的算力消耗大、端側部署局限性大、長序列任務效率低等問題,成為了制約其進一步發展的瓶頸。因此,業界開始圍繞Transformer的Attention機制、FFN層等進行改進,同時也在積極探索非Transformer架構的新路徑,如新型RNN、新型CNN等,每條路徑都有其獨特的代表工作和核心思想。
在架構創新的道路上,行業內部存在著不同的聲音。一方面,有人認為突破智能天花板是當務之急;另一方面,也有人主張通過壓縮智能密度來尋求突破。這兩種觀點雖然看似對立,但實際上卻推動了混合架構逐漸成為趨勢。架構創新也遵循著技術迭代周期律,目前正處于新技術突破的前夜。

報告中展示了多種創新架構的對比圖,清晰呈現了不同架構之間的優勢和劣勢。這些圖表不僅為研究人員提供了直觀的參考,也預示著AI架構領域即將迎來一場深刻的變革。

在這場變革中,誰將成為新的王者尚不得而知。但可以肯定的是,隨著技術的不斷進步和創新探索的不斷深入,AI領域必將迎來更加廣闊的發展空間和更加美好的未來。