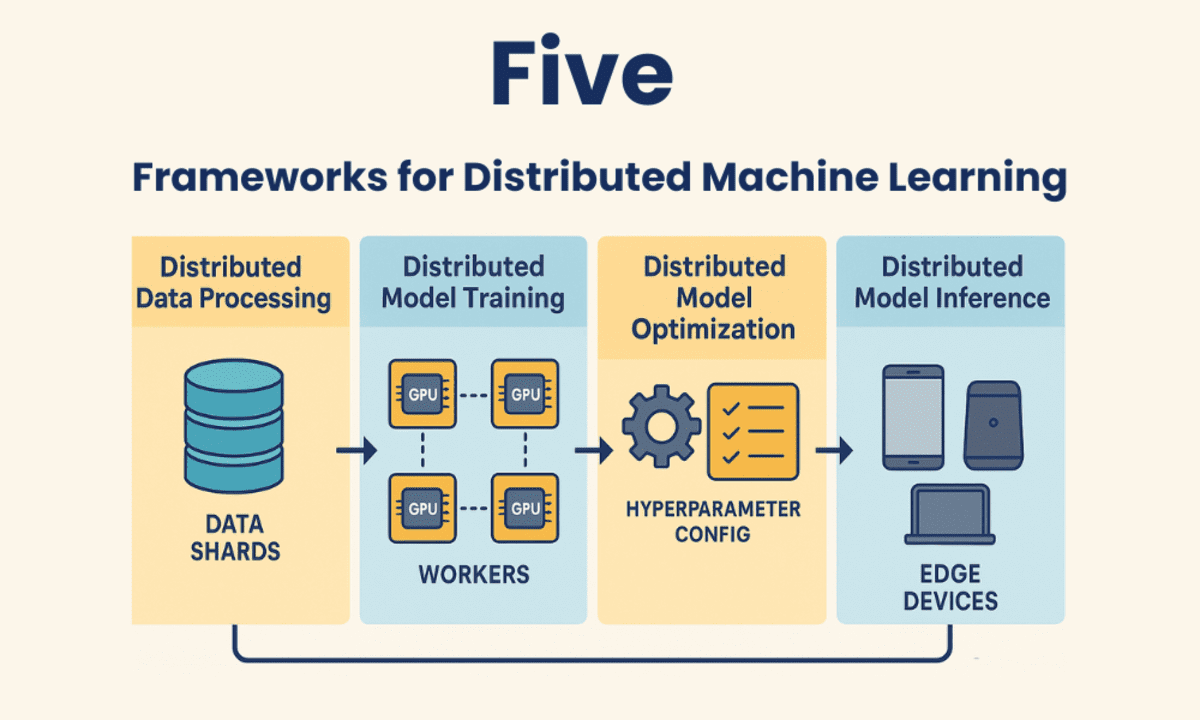
在機(jī)器學(xué)習(xí)和人工智能領(lǐng)域,分布式計(jì)算框架正成為優(yōu)化資源、加速工作流程和降低成本的關(guān)鍵工具。這些框架允許開發(fā)者跨多臺(tái)機(jī)器(無論是CPU、GPU還是TPU)進(jìn)行模型訓(xùn)練,從而顯著縮短訓(xùn)練時(shí)間,并有效處理大型復(fù)雜數(shù)據(jù)集。
在眾多分布式機(jī)器學(xué)習(xí)框架中,PyTorch Distributed以其動(dòng)態(tài)計(jì)算圖、易用性和模塊化設(shè)計(jì)贏得了廣泛認(rèn)可。PyTorch Distributed通過其分布式數(shù)據(jù)并行(DDP)功能,實(shí)現(xiàn)了高效的數(shù)據(jù)分割和梯度同步,支持跨多個(gè)GPU或節(jié)點(diǎn)的模型訓(xùn)練。PyTorch Distributed還支持TorchElastic,實(shí)現(xiàn)了動(dòng)態(tài)資源分配和容錯(cuò)訓(xùn)練,使其在各種規(guī)模的集群上都能表現(xiàn)出色。對于已經(jīng)在使用PyTorch進(jìn)行模型開發(fā)的團(tuán)隊(duì)來說,PyTorch Distributed無疑是一個(gè)增強(qiáng)工作流程的理想選擇。
另一個(gè)備受矚目的框架是TensorFlow Distributed,它是TensorFlow為分布式訓(xùn)練提供的強(qiáng)大支持。TensorFlow Distributed通過tf.distribute.Strategy提供了多種分布式策略,如MirroredStrategy用于多GPU訓(xùn)練,MultiWorkerMirroredStrategy用于多節(jié)點(diǎn)訓(xùn)練,以及TPUStrategy用于基于TPU的訓(xùn)練。TensorFlow Distributed與TensorFlow生態(tài)系統(tǒng)無縫集成,包括TensorBoard、TensorFlow Hub和TensorFlow Serving,使其在大規(guī)模訓(xùn)練深度學(xué)習(xí)模型時(shí)成為首選。TensorFlow Distributed還得到了谷歌云、AWS和Azure等云服務(wù)提供商的大力支持,便于在云端運(yùn)行分布式訓(xùn)練作業(yè)。
除了PyTorch Distributed和TensorFlow Distributed之外,Ray也是一種備受關(guān)注的分布式計(jì)算框架。Ray針對機(jī)器學(xué)習(xí)和AI工作負(fù)載進(jìn)行了優(yōu)化,提供了用于訓(xùn)練、調(diào)優(yōu)和服務(wù)模型的專用庫。Ray Train可以與PyTorch和TensorFlow等流行機(jī)器學(xué)習(xí)框架配合使用,實(shí)現(xiàn)分布式模型訓(xùn)練。Ray Tune則針對跨多個(gè)節(jié)點(diǎn)或GPU的分布式超參數(shù)調(diào)優(yōu)進(jìn)行了優(yōu)化。Ray Serve還提供了用于生產(chǎn)機(jī)器學(xué)習(xí)管道的可擴(kuò)展模型服務(wù)。Ray的動(dòng)態(tài)擴(kuò)展能力使其能夠在小型和大型分布式計(jì)算中都保持高效。
對于處理大規(guī)模結(jié)構(gòu)化或半結(jié)構(gòu)化數(shù)據(jù)的場景,Apache Spark則是一個(gè)不可或缺的選擇。Apache Spark是一種成熟的開源分布式計(jì)算框架,專注于大規(guī)模數(shù)據(jù)處理。其內(nèi)置的MLlib庫提供了機(jī)器學(xué)習(xí)算法的分布式實(shí)現(xiàn),包括回歸、聚類和分類等。Spark可以與Hadoop、Hive以及Amazon S3等云存儲(chǔ)系統(tǒng)無縫集成,使其在處理PB級數(shù)據(jù)時(shí)依然高效。Spark的可擴(kuò)展性使其能夠擴(kuò)展到數(shù)千個(gè)節(jié)點(diǎn),滿足大規(guī)模數(shù)據(jù)處理的需求。
對于希望擴(kuò)展現(xiàn)有工作流程的Python開發(fā)者來說,Dask則是一個(gè)輕量級的選擇。Dask擴(kuò)展了Pandas、NumPy和Scikit-learn等流行Python庫的功能,使其能夠處理內(nèi)存容納不下的數(shù)據(jù)集。Dask可以并行化Python代碼,并以極少的代碼更改將其擴(kuò)展到多個(gè)核心或節(jié)點(diǎn)。Dask還與Scikit-learn、XGBoost和TensorFlow等常用機(jī)器學(xué)習(xí)庫無縫協(xié)作,使其在處理大型數(shù)據(jù)集時(shí)更加高效。
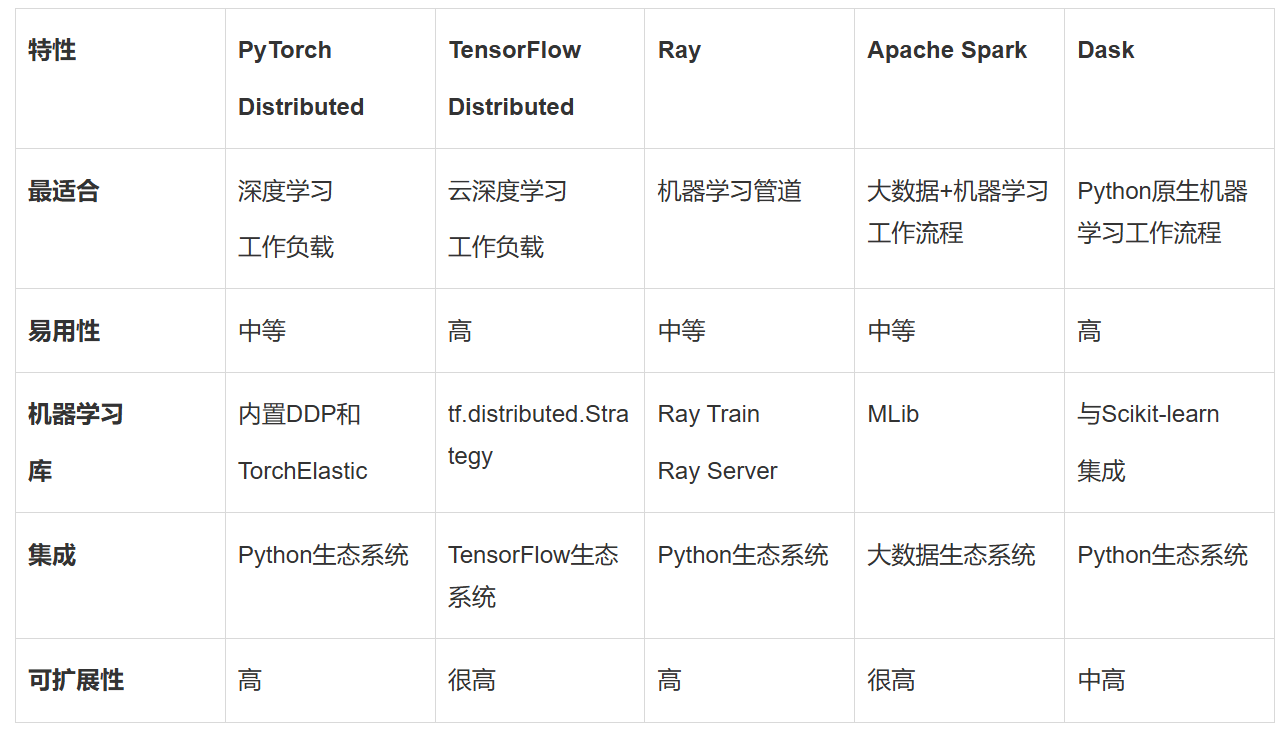
在實(shí)際應(yīng)用中,選擇哪個(gè)分布式機(jī)器學(xué)習(xí)框架取決于具體的需求和項(xiàng)目背景。PyTorch Distributed和TensorFlow Distributed最適合大規(guī)模深度學(xué)習(xí)工作負(fù)載,尤其是當(dāng)團(tuán)隊(duì)已經(jīng)在使用這些框架時(shí)。Ray則非常適合構(gòu)建采用分布式計(jì)算的現(xiàn)代機(jī)器學(xué)習(xí)管道。Apache Spark則是大數(shù)據(jù)環(huán)境中分布式機(jī)器學(xué)習(xí)工作流程的首選解決方案。而對于希望高效擴(kuò)展現(xiàn)有工作流程的Python開發(fā)者來說,Dask則是一個(gè)輕量級且易于上手的選擇。