步入2025年的中點,大模型技術(shù)的飛速發(fā)展令人矚目,尤其以年初DeepSeek的火爆為引爆點,大模型不再局限于實驗室,而是大步流星地融入企業(yè)的核心業(yè)務(wù)系統(tǒng),政務(wù)、金融、醫(yī)療、能源等多個領(lǐng)域紛紛見證了其加速落地的身影。
隨著大模型深入實際應(yīng)用,CTO們的關(guān)注點開始從基礎(chǔ)模型轉(zhuǎn)向推理引擎,推理過程中的資源利用效率——每一度電、每一塊錢、每一分鐘所能產(chǎn)出的Token數(shù)量,已成為衡量企業(yè)在AI時代競爭力的關(guān)鍵標(biāo)尺。如何借助推理引擎提升推理效率、最大化算力價值、盡可能削減推理成本,成為了CTO們亟待解決的重大課題。
大模型在實際應(yīng)用中面臨的一大挑戰(zhàn),便是推理引擎的性能瓶頸。推理引擎,簡而言之,是一套確保大模型高效運行的系統(tǒng),它不僅負責(zé)計算方式,還決定了計算地點和計算速度,旨在最大化提升大模型推理的響應(yīng)速度、并發(fā)能力和算力資源利用率。如果將大模型比作發(fā)動機,推理引擎則是動力總成,決定了發(fā)動機在各種條件下的運行效率。調(diào)校得當(dāng),則能實現(xiàn)低延遲、高吞吐、低成本;調(diào)校不當(dāng),即便是強大的模型也可能出現(xiàn)“高耗低效”的問題。
自2023年起,推理引擎作為獨立賽道逐漸興起,涌現(xiàn)了諸如TGI、vLLM、TensorRT、SGLang等面向推理效率優(yōu)化的開源項目。然而,當(dāng)時業(yè)界主要聚焦于模型訓(xùn)練,對推理引擎的需求尚不迫切。2025年初,以DeepSeek等為代表的大模型開源后,企業(yè)對AI的態(tài)度由觀望轉(zhuǎn)為積極行動,但在落地部署時卻遭遇了推理響應(yīng)慢、吞吐不足、成本高昂等難題。高達90%的算力消耗在推理環(huán)節(jié),卻難以獲得理想的性價比。
大模型推理的難題在于效果、性能、成本之間的“不可能三角”。追求更好的效果,意味著需要更大的模型、更高的精度、更長的上下文,但這會顯著增加算力開銷;追求更快的運行速度,可能需要使用緩存、批處理、圖優(yōu)化等技術(shù),但這可能會影響模型輸出的質(zhì)量;追求更低的成本,則可能需要壓縮模型、降低顯存、使用更經(jīng)濟的算力,但這可能會犧牲推理的性能或準(zhǔn)確率。
面對這些挑戰(zhàn),推理引擎賽道逐漸熱鬧起來。不少在AI應(yīng)用上先行一步的大廠,也意識到了推理引擎的短板,試圖將自身摸索出的經(jīng)驗轉(zhuǎn)化為標(biāo)準(zhǔn)化產(chǎn)品和服務(wù),幫助企業(yè)減輕應(yīng)用負擔(dān)。例如,英偉達推出了推理框架Dynamo,AWS的SageMaker提供了多項增強功能以提高大模型推理的吞吐量、降低延遲并提高可用性,京東云推出了JoyBuilder推理引擎,可將推理成本降低90%。
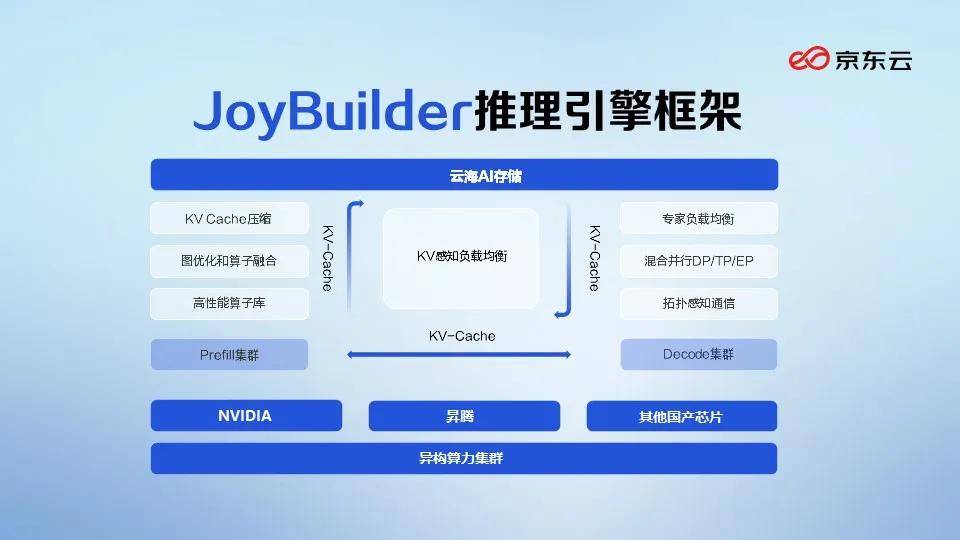
為了提高推理能力,過去主要聚焦于模型優(yōu)化,通過剪枝、蒸餾、量化等技術(shù)給大模型“瘦身”。然而,越來越多的企業(yè)發(fā)現(xiàn),單純的模型優(yōu)化難以顯著提升推理效能,必須優(yōu)化推理流程。大模型的推理過程可以拆解為兩個階段:第一階段是“預(yù)填充”(Prefill),即理解輸入內(nèi)容;第二階段是“解碼”(Decode),即生成輸出內(nèi)容。AWS、京東云、英偉達、谷歌云等企業(yè),都在工程創(chuàng)新方面投入了大量精力。
例如,AWS SageMaker和谷歌云Vertex AI通過優(yōu)化“思考地圖”(即KVCache),建立了緩存共享中心,動態(tài)調(diào)度顯存資源,提高了GPU的利用率。京東云JoyBuilder推理引擎和英偉達的Dynamo則采用了“以存代算”的解決方案,將“思考地圖”從GPU中移出,通過自研的云海AI存儲,支持PB級緩存擴展,大幅降低了多輪對話和長文本處理的響應(yīng)時延。
這些企業(yè)還在探索將“聽”(理解輸入)和“說”(生成輸出)分離,以提高推理吞吐量。AWS不僅實現(xiàn)了“聽”和“說”的分離,還改變了大模型的輸出方式,通過提前整理大綱,減少了思考時間。京東云JoyBuilder推理引擎則采用了不同的方案:一方面與AWS類似,提升了整體吞吐;另一方面,將“聽”和“說”的任務(wù)分配給不同的GPU處理,實現(xiàn)了并行工作,顯著提高了推理吞吐量。
在異構(gòu)算力方面,隨著大模型應(yīng)用的深入,以CPU為中心的架構(gòu)在支持AI原生應(yīng)用上面臨挑戰(zhàn),需要以GPU為中心重塑基礎(chǔ)設(shè)施。然而,異構(gòu)算力,即將不同品牌的芯片混合使用,帶來了新的問題。不同品牌的芯片指令集、運算邏輯都不統(tǒng)一,給管理和調(diào)度帶來了巨大挑戰(zhàn)。目前,vLLM、SGLang等開源引擎在異構(gòu)集群的調(diào)度方面仍顯不足,但國內(nèi)的研究機構(gòu)和科技大廠正在積極尋求解決方案。
一種主流思路是將異構(gòu)算力資源統(tǒng)一管理,按需分配給多個模型和任務(wù)。例如,京東云JoyBuilder推理引擎可以將一張GPU切成多個小份,顯存也能按MB級別分配,從而提高了GPU的利用率。另一種思路是將不同芯片的優(yōu)勢與模型的不同部分相結(jié)合,例如在MoE模型的部署上,可以將不同專家部署在不同GPU上,充分利用不同算力的優(yōu)勢。

大模型已經(jīng)成為新的增長引擎,在營銷推廣、協(xié)同辦公、客戶服務(wù)等場景中深度應(yīng)用。例如,在零售場景,AI生成商品圖、AI營銷內(nèi)容生成、AI數(shù)字人等技術(shù)正在改變用戶的購物體驗。京東云JoyBuilder推理引擎源于京東自身復(fù)雜業(yè)務(wù)場景的打磨,基于企業(yè)級的AI Native架構(gòu),正在廣泛服務(wù)于內(nèi)外部眾多業(yè)務(wù)場景。據(jù)京東透露,推理框架已經(jīng)在內(nèi)部多個場景應(yīng)用,顯著提升了響應(yīng)速度,節(jié)省了計算成本,同時助力了用戶活躍度的提升。
除了服務(wù)于京東內(nèi)部,京東云推理引擎也廣泛服務(wù)于外部產(chǎn)業(yè)客戶,提供高性能、低成本的大模型服務(wù)。在某新能源汽車頭部廠商和某全球新能源科技領(lǐng)導(dǎo)企業(yè)的實踐中,京東云成功打造了覆蓋全集團的智能計算底座,實現(xiàn)了千卡級AI算力集群的精細化管理。通過創(chuàng)新多元算力調(diào)度和創(chuàng)建全生命周期AI開發(fā)環(huán)境,顯著提升了GPU利用率和研發(fā)效率,成為集團的“數(shù)智發(fā)動機”。預(yù)計一年內(nèi),這兩家企業(yè)的大模型訓(xùn)練周期將縮短40%,每年節(jié)省的算力成本相當(dāng)于新建兩座數(shù)據(jù)中心。