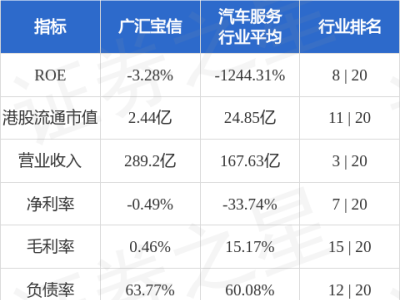
小鵬汽車近日在全球首秀上,發布了一項令人矚目的技術創新,其在20多萬價位的純電動車型上配置了超過2200TOPS的算力,這一舉措無疑開創了行業先河。然而,這一決策也引發了廣泛討論,部分聲音質疑這是否僅僅是一種“堆料”行為,對一味追求算力提升的意義表示懷疑。
針對這些質疑,小鵬汽車在發布會上已做出明確回應。其核心觀點聚焦于大模型的本地部署,這一策略包含兩個關鍵點:大模型與本地部署。在AI時代,模型的能力與參數規模成正比,遵循Scaling Law定律,參數越多,模型表現越佳。然而,受限于車規級芯片算力,目前車端部署的模型普遍經過輕量化處理,實際部署的模型參數量往往在50億以下,如理想的VLA司機大模型僅為40億參數,遠未達到“大模型”的標準。
小鵬的自動駕駛云端基座模型則擁有720億參數的規模,這才是真正意義上的大模型。然而,由于算力限制,這一模型無法在車端實現本地部署。為了突破這一瓶頸,小鵬選擇了將大模型部署到車端,通過3顆自研的圖靈AI芯片,提供2200TOPS的算力,支持最高300億參數的模型運行。從720億到300億,或許只需通過結構化剪枝和MoE轉換即可實現,性能差距遠小于從720億到更小的模型規模的轉換。
有人或許要問,既然5G時代已經到來,為何不考慮云端大模型?這確實能降低車端算力的需求。然而,行車模型對時延和幀數的要求極高,云端部署難以滿足。何小鵬在發布會上提到,VLA模型至少需要達到每秒20幀才能保證足夠的行車能力,這意味著從感知到數據傳輸、云端處理再到結果回傳的總耗時必須在50毫秒以內完成,這在云端部署中難以實現。網絡波動和通訊失效的風險也無法完全避免,這可能導致車端系統降級或癱瘓,影響用戶體驗和系統安全。
另一方面,全本地部署、無聯網運行還意味著沒有數據傳輸的合規問題,這使得模型具備在全球范圍內快速部署的能力。只需在部署前針對當地市場進行本地化訓練,即可滿足不同地區的需求。
在小鵬G7車型上,這一策略得到了具體體現。G7采用2顆圖靈芯片(共1400+TOPS)運行VLA模型(VLA-OL,具備自主強化學習能力),另1顆圖靈芯片(700+TOPS)則用于運行VLM模型。這種架構下,VLA負責車輛的運動控制,如同大腦和小腦;而VLM則負責車輛對世界的感知,如同整車的大腦。VLA需要更大的算力來保證每秒20幀的性能,而VLM則只需每秒幾幀的性能即可滿足需求。
盡管如此,本地部署的VLA OL+VLM組合仍然給人留下了巨大的想象空間。何小鵬在發布會上提到的“智駕能力比Max車型高10倍以上”,“VLA-OL讓車輛主動思考、理解世界”,“VLM讓車像一個真實的人”等描述,都基于這一大算力平臺。這一切的實現,都離不開大算力的支持。
隨著小鵬G7的全球首秀,這一創新技術也將接受市場的檢驗。無論是對于小鵬汽車還是整個汽車行業來說,這都是一次具有里程碑意義的嘗試。
在未來,隨著技術的不斷進步和市場的逐步成熟,我們有理由相信,更多創新技術將不斷涌現,推動汽車行業向更加智能化、自動化的方向發展。