基石智算CoresHub近期對其模型推理服務進行了全面革新,為用戶帶來了更加便捷高效的模型部署與推理體驗。現在,用戶可以在魔搭、Hugging Face等平臺輕松下載模型,并直接通過基石智算的推理服務進行一鍵部署,快速對外提供API接口能力。用戶還可以選擇利用基石智算的模型調優(yōu)服務進行二次訓練,進一步提升模型性能后再進行部署。
在推理服務過程中,基石智算憑借其強大的彈性擴縮容能力,能夠根據業(yè)務并發(fā)量的實際需求,靈活調整推理服務的規(guī)模。這一特性不僅顯著提升了業(yè)務的運行效率,還有效降低了算力成本,為用戶帶來了實實在在的經濟效益。
以下是一個以從魔搭下載模型為例,通過基石智算模型推理服務一鍵部署模型的詳細操作流程:
首先,用戶需要在魔搭平臺上選擇并下載所需的模型文件,然后將這些文件存儲到指定的存儲目錄中。為了完成這一步驟,用戶可以創(chuàng)建一個無卡啟動實例,并掛載文件存儲,以便在Web連接窗口中執(zhí)行相關命令。
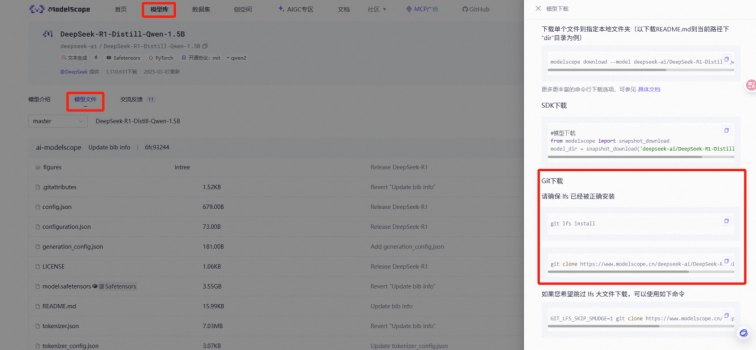
在Web連接窗口中,用戶可以查看魔搭平臺提供的模型下載命令,并使用Git工具進行下載。如果遇到大文件下載失敗的情況,用戶還可以執(zhí)行相應的代碼來解決這一問題。
接下來,用戶需要進入基石智算的“模型管理”界面,添加已下載的模型。在這一步驟中,用戶需要選擇模型文件、輸入模型名稱等相關信息,并選擇適合的部署方式。基石智算支持單節(jié)點和多節(jié)點部署,用戶可以根據實際需求進行選擇。
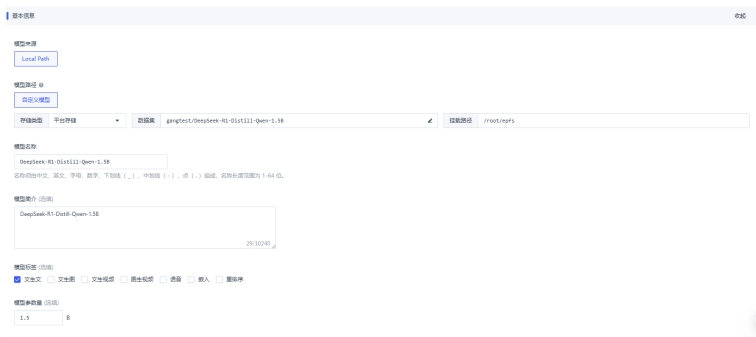
在選擇部署方式后,用戶還需要選擇資源類型,如GPU等,以滿足模型的推理需求。部署成功后,用戶可以在服務信息界面查看服務詳情、監(jiān)控信息和日志記錄,以便隨時了解模型的運行狀態(tài)。
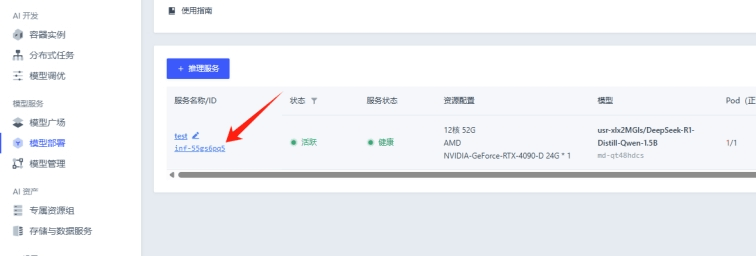
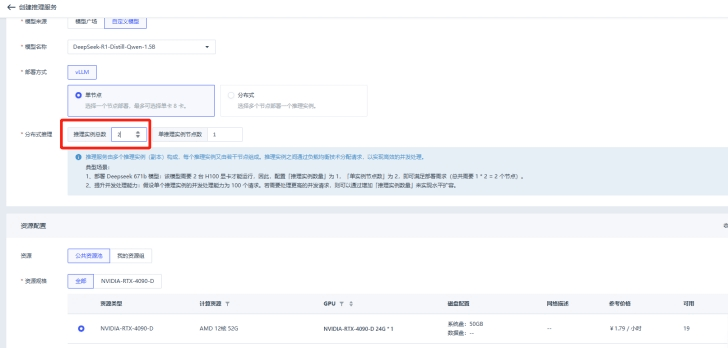
當業(yè)務并發(fā)量增加時,用戶可以通過增加推理實例的數量來擴展推理服務的規(guī)模,以滿足更高的并發(fā)需求。例如,當一張4090顯卡無法滿足DeepSeek-R1-1.5B模型的最高100并發(fā)量時,用戶可以增加到兩張4090顯卡的實例進行部署。
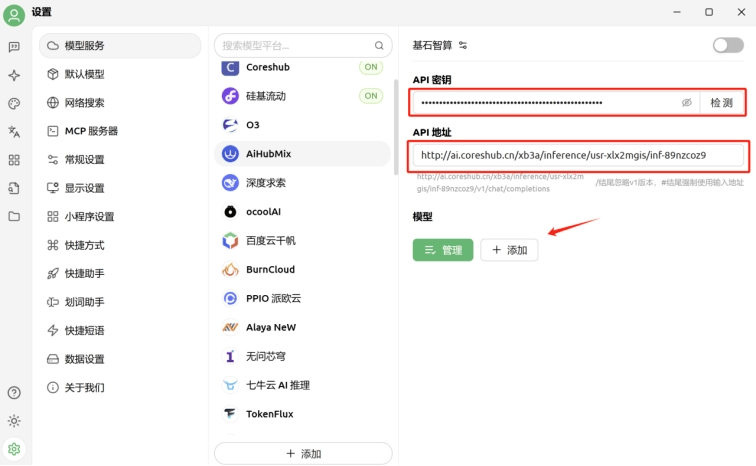
最后,用戶可以使用第三方客戶端如Cherry Studio來調用已部署的模型。用戶只需在Cherry Studio中添加模型服務提供商,并配置相應的API密鑰和API路徑,即可在平臺上輕松切換并使用已添加的模型進行對話等操作。