近日,AI領域傳來了一項新的技術突破,DeepSeek團隊發布了其最新的研究成果——DeepSeek-V3。這篇論文不僅深入探討了DeepSeek在硬件架構和模型設計方面的創新,還為實現高效益的大規模訓練和推理提供了寶貴的思路。
據悉,DeepSeek的創始人兼CEO梁文鋒也參與了此次論文的撰寫,并在作者名單中占據了重要位置。論文的通訊地址顯示為中國北京,這暗示著此次研究很可能由DeepSeek的北京團隊主導。
隨著大語言模型的快速發展,硬件架構的瓶頸逐漸顯現,包括內存容量不足、計算效率低下以及互連帶寬受限等問題。然而,DeepSeek-V3卻成功地在這些方面取得了顯著的突破。
據透露,DeepSeek-V3僅在2048塊H800 GPU上進行訓練,就實現了FP8訓練準確率損失小于0.25%的驚人表現,每token的訓練成本僅為250 GFLOPS。相比之下,405B密集模型的訓練成本高達2.45 TFLOPS,而KV緩存更是低至每個token 70 KB,僅為Llama-3.1緩存的1/7。
那么,這些令人矚目的數據背后,到底隱藏著怎樣的技術革新呢?DeepSeek在論文中詳細闡述了其模型架構和AI基礎設施的關鍵創新。其中,包括用于提高內存效率的多頭潛在注意力(MLA)、用于優化計算-通信權衡的混合專家(MoE)架構、用于釋放硬件全部潛力的FP8混合精度訓練,以及用于減少集群級網絡開銷的多平面網絡拓撲。
DeepSeek-V3的基本架構圖展示了這些創新如何協同工作,以實現高效的大規模訓練和推理。論文指出,有效的軟硬件協同設計可以為較小的團隊提供與大團隊競爭的公平環境,這也在一定程度上解釋了DeepSeek-V3為何能夠取得如此顯著的突破。
在論文中,DeepSeek詳細探討了硬件驅動的模型設計、硬件和模型之間的相互依賴關系以及硬件開發的未來方向。其中,從源頭優化內存效率是DeepSeek-V3解決擴展挑戰的關鍵之一。通過使用MLA減少KV緩存,DeepSeek成功降低了內存消耗,從而有效緩解了AI內存墻的挑戰。
DeepSeek還開發了DeepSeekMoE,利用MoE模型的優勢降低訓練成本和便于本地部署。MoE模型允許參數總數急劇增加,同時保持計算要求適中,這為個人使用和本地部署提供了獨特的優勢。
在推理速度方面,DeepSeek通過重疊計算和通信、引入高帶寬縱向擴展網絡以及多token預測框架等技術,成功提高了模型的推理速度。這些創新不僅實現了全對全通信與正在進行的計算的無縫重疊,還充分利用了GPU資源,從而顯著提高了吞吐量。
在具體技術實現方面,DeepSeek采用了FP8混合精度訓練,將模型內存占用直接減少了50%。同時,團隊還提出了LogFMT對數空間量化方案,在相同比特下實現了更高精度。在互連優化方面,DeepSeek摒棄了傳統張量并行(TP),轉而采用流水線并行(PP)和專家并行(EP),配合自主研發的DeepEP庫,實現了通信效率的飛躍。
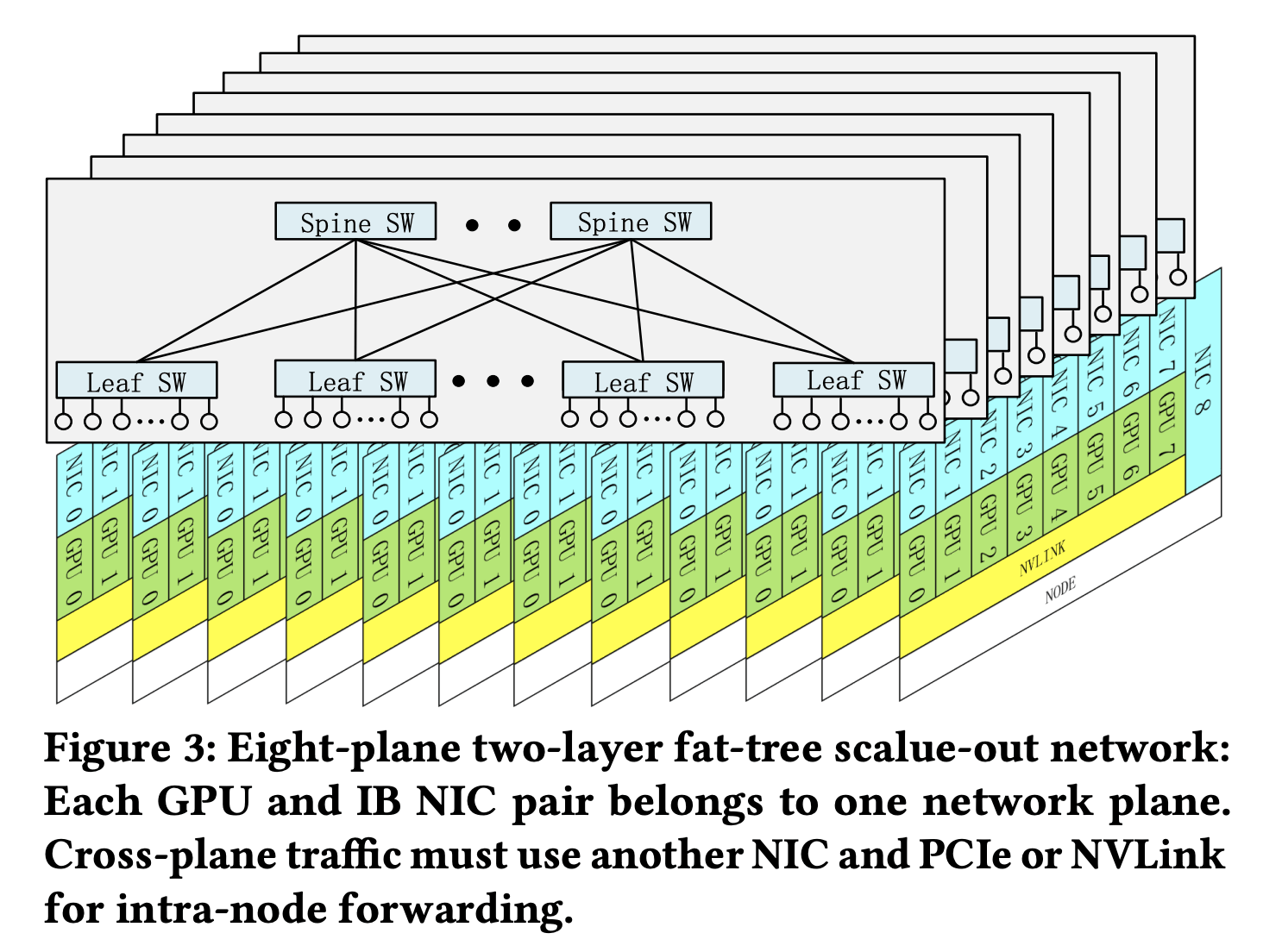
DeepSeek還推出了兩層多層胖樹(MPFT)網絡拓撲,通過8個獨立平面實現故障隔離與負載均衡。這一創新不僅降低了成本40%以上,還在全到全通信性能上與單層多軌網絡相當,為集群擴展提供了堅實保障。
在論文的結尾部分,DeepSeek從硬件架構演進的角度提出了六大未來挑戰與解決方案,涵蓋了內存、互連、網絡、計算等核心領域。這些建議不僅為下一代AI基礎設施的升級提供了方向,也為整個AI產業的發展提供了重要參考。