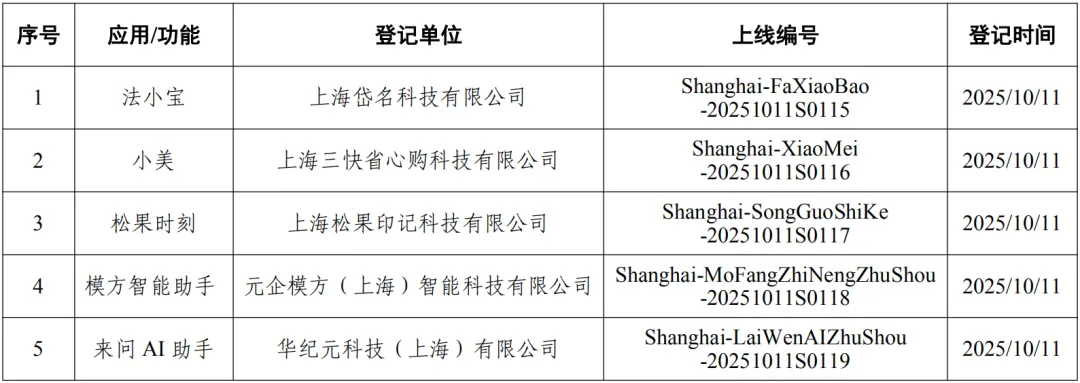
在2025人工智能計算大會上,浪潮信息推出的元腦SD200與HC1000兩款AI服務器成為焦點。這兩款產品通過底層架構創新,在DeepSeek R1大模型運行中實現了8.9毫秒的Token生成速度,并將推理成本壓縮至每百萬Token僅1元,為智能體產業化提供了關鍵技術支撐。
8.9毫秒的響應速度意味著什么?人類眨眼需要100-400毫秒,而AI生成每個Token的時間比眨眼快數十倍。這種突破使AI交互從"延遲對話"邁向"實時響應",用戶提問與系統反饋幾乎同步完成。傳統AI服務中常見的"逐字輸出"現象,在此技術支撐下徹底成為歷史。
支撐這一速度的核心是"多主機3D Mesh"系統架構。該架構通過在單個機箱內集成64顆國產AI芯片,構建了高效的數據傳輸網絡。其專用互連協議采用三層精簡設計,原生支持內存語義,將通信延遲壓縮至百納秒級。配合自研的Smart Fabric Manager技術,系統可動態規劃最優通信路徑,實現0.69微秒的行業最低延遲。
這項技術突破的影響遠超聊天機器人領域。在金融高頻交易中,毫秒級延遲可能決定交易成敗;自動駕駛場景下,數據響應速度直接影響行車安全;工業自動化領域,通信效率直接關乎生產效率。智能體時代的競爭本質是速度競爭,技術落后者將面臨淘汰風險。
成本方面的突破同樣具有顛覆性。HC1000服務器通過"全對稱DirectCom極速架構",將推理成本降至1元/百萬Token。這一價格使AI服務從"企業專屬"變為"普惠資源",中小企業和個人開發者均可負擔大規模AI應用。傳統架構中計算與通信分離導致的效率損失,在此被"邊算邊傳"的流水線模式徹底解決。
該架構的創新點在于計算單元與通信通道的1:1直連設計,實現全局無阻塞通信。支持從1024卡擴展至52萬卡的超大規模部署能力,使單卡成本降低60%以上。這種設計讓AI推理成本接近人力成本,未來企業可能以"實習生團隊"的預算,獲得7×24小時工作的AI智能體服務。
浪潮的技術突破標志著AI競爭焦點轉移。過去行業聚焦模型參數規模,如今轉向速度與成本的底層優化。再強大的模型,若缺乏高效計算架構支撐,終將淪為實驗室展示品。這如同制造超級跑車卻無配套高速公路,性能優勢無法轉化為實際價值。
中國AI產業正從應用創新向基礎設施創新深化。當速度與成本不再是障礙,智能體技術才能真正扎根現實場景。這場由浪潮引發的技術變革,或將催生改變世界的超級應用,其影響可能遠超當前預期。