英偉達近日宣布推出OpenReasoning-Nemotron模型,這一創(chuàng)新成果基于Qwen2.5架構(gòu),并利用DeepSeek-R1-0528生成的數(shù)據(jù)進行訓(xùn)練,展示了在數(shù)學(xué)、科學(xué)和代碼任務(wù)上的卓越推理能力。
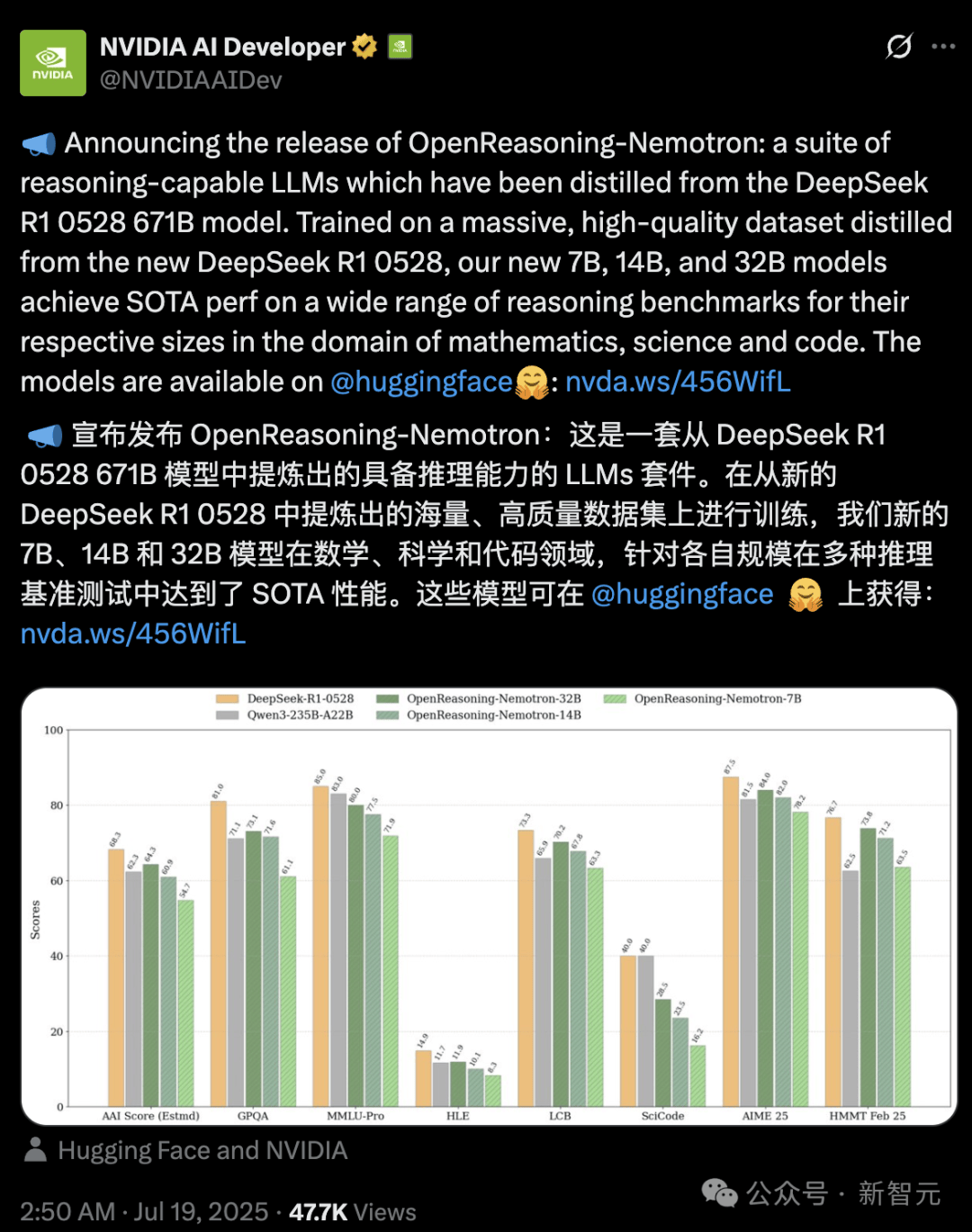
據(jù)悉,OpenReasoning-Nemotron在多個基準測試中刷新了記錄,特別是在數(shù)學(xué)領(lǐng)域,其表現(xiàn)超越了先前的標桿模型o3。這一突破引發(fā)了業(yè)界的廣泛關(guān)注,人們紛紛猜測,開源模型領(lǐng)域的王座或?qū)⒃俅胃?/p>
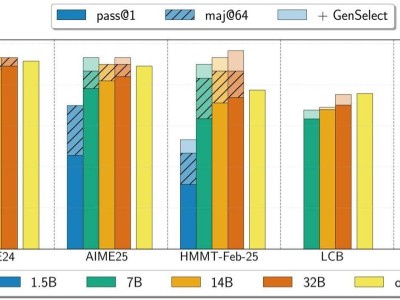
英偉達此次推出的模型提供了四種參數(shù)規(guī)模,分別是1.5B、7B、14B和32B,用戶可以在本地實現(xiàn)100%運行。盡管這些模型帶有“國產(chǎn)血統(tǒng)”——其架構(gòu)基于Qwen2.5,SFT訓(xùn)練數(shù)據(jù)由DeepSeek-R1-0528生成,但它們在推理能力上的表現(xiàn)卻毫不遜色。
OpenReasoning-Nemotron被公認為當(dāng)前最強的蒸餾推理模型。英偉達研究科學(xué)家Igor Gitman介紹了該模型的亮點,指出它不僅僅進行token預(yù)測,而是實現(xiàn)了真正的推理能力。這一突破得益于DeepSeek-R1-0528的蒸餾,該模型在5M的數(shù)學(xué)、代碼和科學(xué)推理軌跡上進行了訓(xùn)練。
值得注意的是,OpenReasoning-Nemotron在沒有進行任何在線強化學(xué)習(xí)的情況下,僅通過有監(jiān)督微調(diào)(SFT)就取得了如此顯著的成果。未來,隨著進一步優(yōu)化或使用更少的token,這些模型有望實現(xiàn)相似甚至更好的性能。
除了在數(shù)學(xué)基準測試中超越OpenAI o3(高算力版)外,OpenReasoning-Nemotron還展現(xiàn)出了從數(shù)學(xué)到代碼的泛化能力。盡管這些模型僅針對數(shù)學(xué)問題訓(xùn)練了GenSelect算法,但它們在代碼任務(wù)上也取得了令人驚訝的結(jié)果。
然而,英偉達也澄清,這是一次“研究性質(zhì)”的模型發(fā)布,主要目標是驗證新生成數(shù)據(jù)的價值,并探索僅通過監(jiān)督微調(diào)能將性能推到何種程度。因此,這些模型目前可能無法勝任多輪對話或作為通用助手。
盡管如此,OpenReasoning-Nemotron在多個具有挑戰(zhàn)性的推理基準測試中仍表現(xiàn)出色,7B、14B和32B模型在各自規(guī)模類別下均創(chuàng)下了多項最先進紀錄。這一成果不僅展示了英偉達在AI領(lǐng)域的深厚積累,也為未來的推理模型研究提供了新的基線。
英偉達還發(fā)現(xiàn)了一些有趣的現(xiàn)象。例如,參數(shù)規(guī)模對模型性能的影響巨大,1.5B模型在處理較長上下文生成時可能不太一致,而7B或更大的模型則表現(xiàn)出了顯著的進步。模型還學(xué)會了兩種不同的行為:一種是使用工具但推理較差,另一種是不使用工具但推理很強。
為了讓更多用戶能夠體驗OpenReasoning-Nemotron模型的強大功能,英偉達提供了詳細的本地運行指南和模型鏈接。用戶只需下載適用于macOS、Windows或Linux的LM Studio,在搜索標簽頁輸入“openreasoning”,即可安裝所需版本的模型。

英偉達的這一創(chuàng)新成果無疑為AI領(lǐng)域帶來了新的活力,也為未來的推理模型研究指明了方向。隨著技術(shù)的不斷進步和應(yīng)用場景的不斷拓展,我們有理由相信,AI將在更多領(lǐng)域展現(xiàn)出其獨特的價值和潛力。