在AI界掀起波瀾的最新動態中,谷歌以雙重策略震撼了大模型戰場。一方面,T5Gemma的橫空出世重新點燃了encoder-decoder架構的戰火,性能實現了顯著提升;另一方面,MedGemma則堅守decoder-only路線,強勢進軍醫療多模態領域,打破了閉源壁壘。
自2023年以來,decoder-only架構幾乎壟斷了大模型的江湖。從GPT系列到LLaMA、Gemma、Mistral,再到Claude、Command-R、Yi系列,主流的大語言模型(LLM)幾乎清一色采用了這種“純解碼器”設計。然而,谷歌攜T5Gemma的回歸,打破了這一局面。
T5Gemma不僅重啟了encoder-decoder的技術路線,而且通過簡單的“適配”就實現了性能的飛躍,遠遠超過了原版Gemma 2。這一轉變令人矚目,T5Gemma 9B-9B在GSM8K(數學推理)上的得分比原始Gemma 2 9B高出9分,在DROP(閱讀理解)上的得分也高出4分。更令人驚訝的是,當進一步縮小參數量時,T5Gemma 2B-2B IT的MMLU得分比Gemma 2 2B提高了近12分,GSM8K準確率暴漲到70.7%。
T5Gemma主要針對文本生成任務,包括問答系統、數學推理、閱讀理解等。其encoder-decoder架構支持“不平衡”配置,例如9B編碼器配2B解碼器,能在質量和效率之間實現最佳平衡。在相同的計算量下,T5Gemma的性能優于僅解碼器模型,且靈活度更高,可以根據具體任務調整編碼器和解碼器的大小。
除了T5Gemma的技術回馬槍,Gemma 3系列也迎來了重大更新。谷歌此次專注于醫療多模態任務,推出了MedGemma和MedSigLIP兩款多模態模型。MedGemma支持圖文輸入,輸出醫學自由文本;而MedSigLIP則是輕量圖文編碼器。谷歌將“低資源友好”理念貫徹到底,MedGemma僅需4B模型即可逼近當前最優水平(SoTA),部署門檻極低,單卡甚至移動端也能輕松運行。
4億參數的MedSigLIP同樣表現出色,不僅在醫學圖像領域游刃有余,還擅長檢索、零樣本分類等非醫學下游任務。在Med系列的“開源雙子星”的推動下,醫療模型的閉源壁壘岌岌可危,同行們紛紛對谷歌表示祝賀和期待。
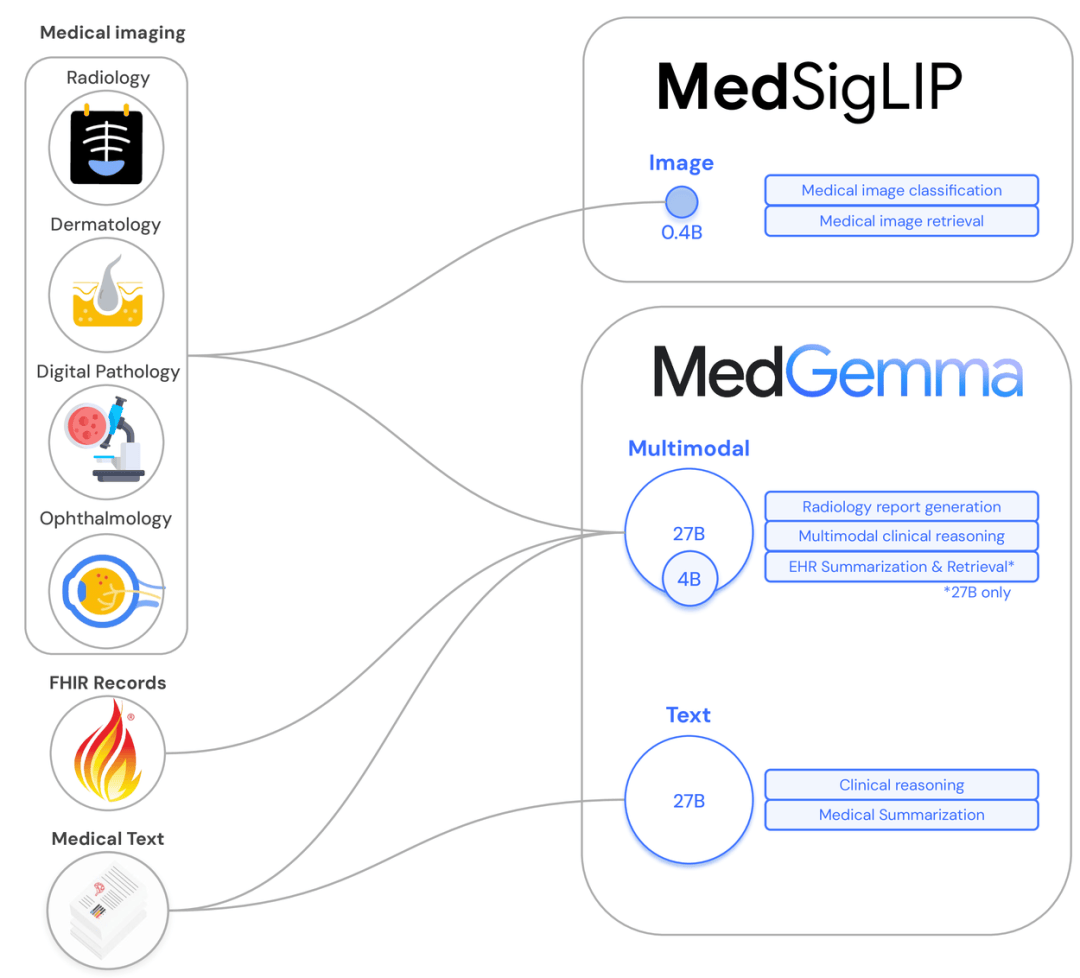
谷歌的T5Gemma和Med系列模型不僅在架構上實現了革新,更在產業落地方面邁出了堅實步伐。T5Gemma系列預訓練模型和指令微調模型已在Hugging Face上開源,助力社區在研究與開發中挖掘新機遇。而MedGemma和MedSigLIP的發布,更是直接將醫療AI的開源門檻大幅降低,醫療機構可以輕松下載、部署,并在本地或自定義云平臺完成推理與微調。
谷歌的這一波操作,不僅打破了閉源神話,更為整個AI社區樹立了“工具+自由+性能”的典范。從T5Gemma到MedGemma,世界級開源模型已經到來,接下來,就看開發者們如何大顯身手了。