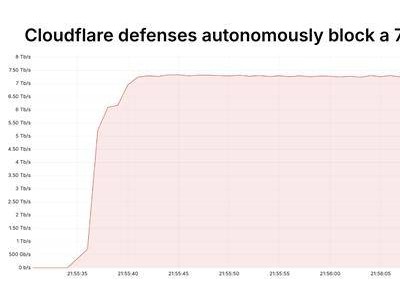
AI大模型(LLM)掀起的生成式革命,正重塑各行各業,連我們每天刷到的推薦系統也不例外。
傳統推薦系統像一條多環節的“流水線”(級聯架構),容易導致算力浪費、目標沖突,制約了發展。要突破瓶頸,關鍵在于用LLM技術進行“一體化”重構,實現效果提升和成本降低。
快手技術團隊最新提出的 「OneRec」 系統,正是這一思路的突破。它首次用端到端的生成式AI架構,徹底改造了推薦系統的全流程,在效果和成本上實現了“既要又要”:
● 效果猛增: 有效計算量提升10倍!讓強化學習技術在推薦場景真正“活”了起來,推薦更精準。
● 成本銳減: 通過架構革新,訓練和推理的算力利用率(MFU) 分別飆升至 23.7% 和 28.8%,運營成本(OPEX)僅為傳統方案的10.6%!
目前,該系統已在快手 App / 快手極速版雙端服務所有用戶,承接約 25% 的QPS(每秒請求數量),帶動 App 停留時長提升 0.54%/1.24%,關鍵指標 7 日用戶生命周期(LT7)顯著增長,為推薦系統從傳統 Pipeline 邁向端到端生成式架構提供了首個工業級可行方案。
完整技術報告鏈接:https://arxiv.org/abs/2506.13695
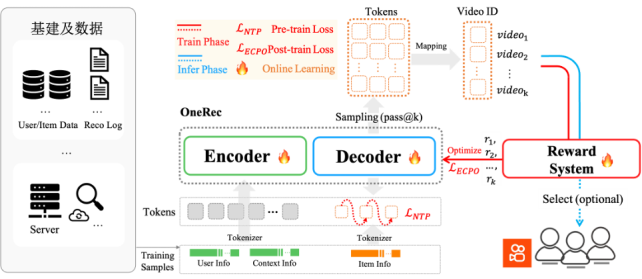
(圖: OneRec 系統概覽)
OneRec 基礎模型剖析
OneRec 采用端到端生成式架構,首創協同感知多模態分詞器:通過融合視頻標題、圖像等多維信息與用戶行為,利用 RQ-Kmeans 分層生成語義 ID。其 Encoder-Decoder 框架將推薦轉化為序列生成任務:
● Encoder 整合用戶終身/短期行為序列實現多尺度建模;
● MoE 增強的 Decoder 通過 Next Token Prediction 精準生成推薦結果。
● 實驗驗證其遵循 Scaling Law——參數量增至 2.633B 時訓練損失顯著下降,結合特征/碼本/推理級優化,實現效果與算力的協同突破。
強化學習(RL)偏好對齊
OneRec 突破傳統推薦依賴歷史曝光的局限,創新引入強化學習偏好對齊機制。通過融合 偏好獎勵(用戶偏好)、格式獎勵(有效輸出) 及 業務獎勵(工業需求) 構建綜合獎勵系統,并利用 個性化P-Score 作為強化信號。采用改進的 ECPO算法(嚴格截斷負優勢梯度)提升訓練穩定性,在快手場景中實現 不損失曝光量前提下顯著提升用戶時長,達成工業級效果突破。

性能優化
在性能優化上,OneRec突破傳統推薦MFU個位數魔咒:通過架構重構+算子壓縮92%至 1,200 個,訓練/推理MFU提升至23.7%/28.6%,算力效能達主流AI模型水平,實現3-5倍躍升。首次讓推薦系統達到與主流 AI 模型比肩的算力效能水平。
此外,快手技術團隊還針對 OneRec 特性在訓練和推理框架層面進行了深度定制優化。訓練側采用請求分組特征復用與變長Flash Attention提升計算密度,自研SKAI系統實現Embedding全流程GPU訓練,徹底消除CPU同步瓶頸;推理側首創計算復用架構——Encoder單次前向+Beam間KV共享+Decoder層KV Cache,支撐512大Beam Size生成需求,并基于Float16混合精度與MoE/Attention算子深度融合提升吞吐。最終訓練/推理MFU達23.7%/28.8%(較傳統模型提升3-5倍),運營成本降至傳統方案10.6%,實現近90%成本節約。
Online實驗效果
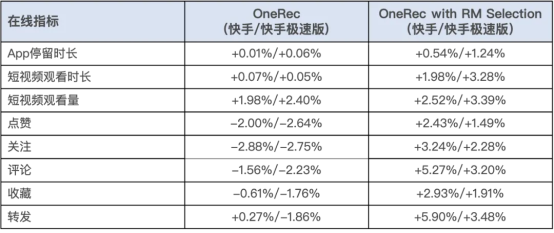
該模型經過一周 5% 流量 AB 測試,在點贊、關注、評論等所有交互指標上均獲正向收益(如下圖)。系統現已全量覆蓋短視頻推薦主場景,承擔約 25% QPS。除了短視頻推薦的消費場景之外,OneRec 在快手本地生活服務場景同樣表現驚艷:AB 對比實驗表明該方案推動 GMV 暴漲 21.01%、訂單量提升 17.89%、購買用戶數增長 18.58%,其中新客獲取效率更實現 23.02% 的顯著提升。目前,該業務線已實現 100% 流量全量切換。
生成式 AI 方興未艾,正引發各領域根本性技術變革與降本增效。OneRec 不僅論證了推薦系統與 LLM 技術棧深度融合的必要性,更重構了互聯網核心基礎設施的技術 DNA。隨著其新范式的到來,推薦系統將加速迎來「端到端生成式覺醒」時刻。