在近期舉辦的2025智源大會上,面壁智能這家北京的大模型創新企業,推出了其開源模型MiniCPM 4.0的兩個新版本,分別為0.5B和8B,內部代號“前進四”。這一發布引起了業內廣泛關注。
據悉,MiniCPM4-0.5B的訓練成本僅為Qwen3-0.6B的2.7%,卻以一半的參數量實現了性能翻倍,綜合得分平均分高達52.06分,遠超同類模型。更為出色的是,面壁智能還推出了一個0.5B的三級量化版本,平均得分更是達到了56分,這一成績實屬不易。
而MiniCPM4-8B的表現同樣令人矚目。其訓練開銷僅為22%,并加入了長上下文稀疏化版本,使得同等參數下性能更強。在同類端側模型排行榜中,MiniCPM4-8B的綜合得分甚至超越了Gemma3-12B,與Qwen3-8B比肩,位居榜首。
面壁智能CEO李大海在會上表示,MiniCPM4模型的最大特點就是速度快。在處理極端場景下的140K上下文時,需要極大的端側內存。而在Jetson Orin AGX(64G)或RTX 4090(24G)硬件上運行128K長文本時,像Qwen3-8B這樣未進行上下文稀疏化的模型,顯存往往不夠用,需要借助CPU內存,這會導致速度急劇下降。而MiniCPM4-8B則通過快速稀疏化工作,將占用的低長文本緩存降至1/4,在常規場景中至少可以取得3-5倍的速度優勢。
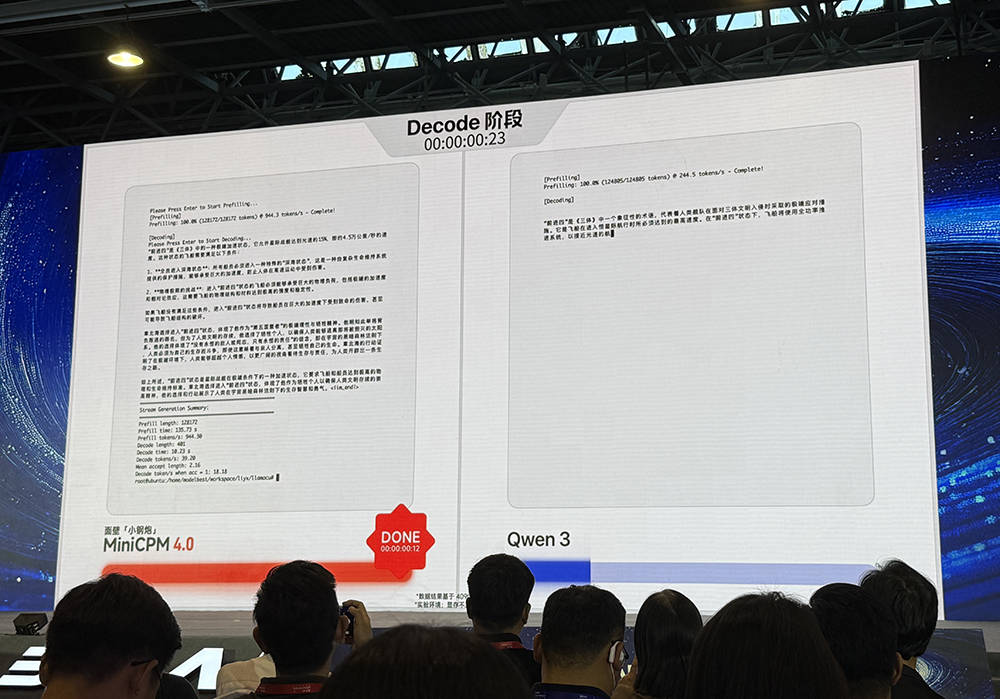
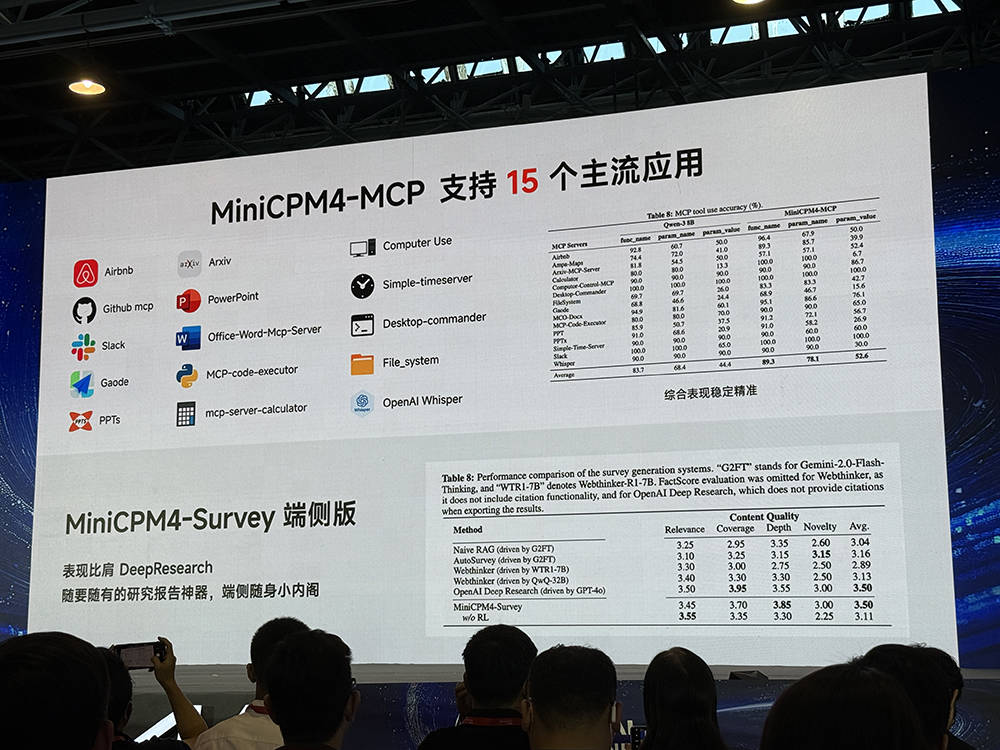
李大海進一步透露,在顯存受限的極限場景中,MiniCPM4的測試數據甚至可以達到220倍的速度提升。面壁智能的MiniCPM4-MCP模型在端側利用MCP協議,支持15個主流應用,綜合評測表現得分頗高。而另一個MiniCPM4-Survey端側版則可在AI PC上構建深度研究服務,成為離線可用的隨身研究報告工具,有助于保護本地隱私數據。
值得注意的是,面壁智能與英特爾緊密合作,首次在端側解鎖了128K長上下文窗口。在英特爾平臺上,基于InfLLM 2.0稀疏注意力結構,實現了3.8倍加速的推理優化效果。同時,MiniCPM4已經可以在華為昇騰、聯發科、高通等主流芯片上流暢運行,并支持vLLM、AutoGPT等推理框架,歐拉版也正在積極適配中。
那么,面壁智能是如何實現MiniCPM4又快又好的表現的呢?李大海分享了背后的技術細節。他提到,這是行業首個全開源系統級上下級稀疏化高效創新。MiniCPM4采用了InfLLM 2.0混合稀疏注意力結構,通過分塊分區域處理文本,只對最具相關性的重點區域進行注意力計算,從而大大提高了效率。同時,面壁智能還創新地采用了高效的自動雙頻換擋技術,長文本用稀疏方案,短文本用稠密方案,進一步提升了性能。

在推理方面,面壁智能自研了全套端側高性能推理框架,包括實現稀疏、投機和量化的高效結合的CPM.cu,極致低位寬量化的BitCPM,以及面向多平臺端側芯片極致優化的Arkinfer。這些創新使得MiniCPM4在端側的表現更加出色。