聲網與RTE開發者社區攜手,近期宣布了兩項重要成果:TEN VAD與TEN Turn Detection模型的開源。這兩款模型是聲網基于其超過十年的實時語音技術研究,以及超低延遲技術積累所打造的,旨在大幅提升AI Agent的交互體驗,使其更加自然流暢。作為開源項目,全球開發者均可自由使用、修改和貢獻代碼,它們也將作為開源對話式AI生態體系TEN的核心組件,持續進行優化迭代。
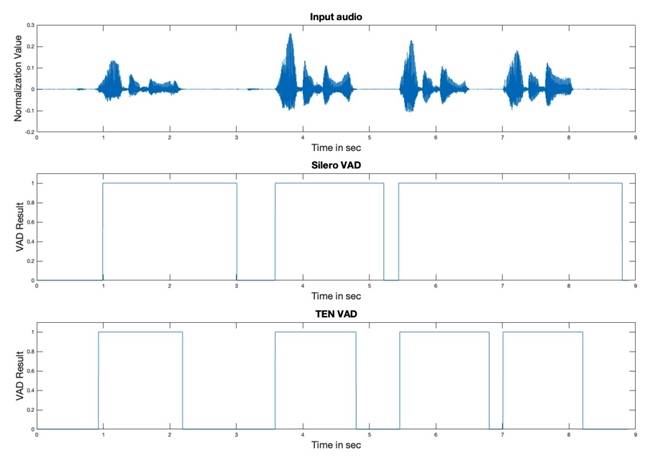
TEN VAD,一款輕量級、高性能的語音活動檢測模型,憑借其超低延遲、低功耗和高準確率的特點,在語音輸入大語言模型前的預處理階段發揮著重要作用。它能夠精確識別音頻中的人聲,并有效過濾掉背景噪音和靜音段,不僅提升了語音識別(STT)的準確性,還顯著降低了處理成本。與WebRTC Pitch VAD和Silero VAD相比,TEN VAD在公開測試集上展現出了更優越的表現,特別是在延遲方面,TEN VAD能夠快速檢測語音與非語音的切換,避免了因延遲導致的交互不暢。
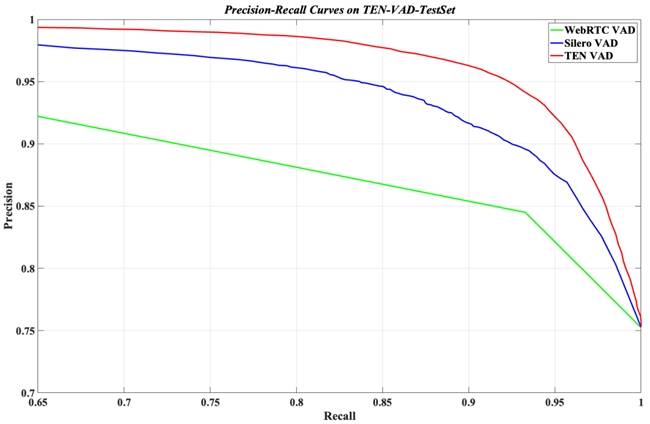
TEN VAD已在Hugging Face和GitHub上開源,并配備了人工精標的數據集,方便開發者進行模型推理和評估。實際應用中,一個真實用戶案例顯示,使用TEN VAD后,音頻傳輸數據量減少了62%,語音服務成本大幅降低。
另一款模型,TEN Turn Detection,則專注于解決人機對話中的一大難題:判斷用戶何時停止說話。在真實交流中,AI需要準確區分用戶的“中途停頓”與“表達完畢”,以避免插話打斷或回應遲緩。TEN Turn Detection支持全雙工語音交互,允許用戶和AI同時說話,使對話更加自然。該模型通過分析語言模式,判斷說話者的狀態,從而智能決定AI是“說”還是“聽”,支持中英文,可供所有Voice Agent開發者使用。
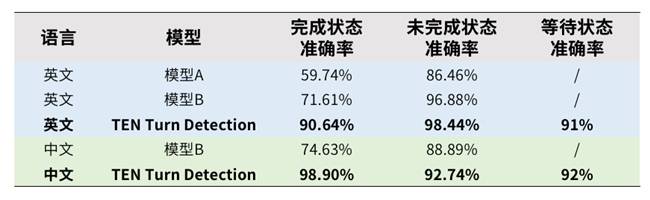
在多場景測試數據集上,TEN Turn Detection與其他同類開源模型相比,表現出了優越的性能。當TEN VAD與TEN Turn Detection結合使用時,可以打造出更自然、反應更迅速、成本更低的Voice Agent。這兩款模型都基于聲網深厚的實時語音研究經驗,擁有超低延遲、低功耗和高準確率的特點,且完全開源,采用Apache 2.0許可證。
使用這兩款模型,AI Agent能夠正確處理“打斷”、“停頓”、“回應”等人類式交互,極大提升用戶體驗。同時,由于VAD能夠準確識別語音幀,有效減少語音識別調用量,實測結果顯示,兩者合用能大幅降低總系統成本。這兩款模型還可以作為TEN framework的插件模塊使用,對于已經使用TEN framework的開發者,支持無縫集成;對于正在選型AI Agent框架的團隊,TEN無疑是具備最佳VAD和輪次檢測能力的選擇之一。
為了快速體驗這兩款模型,開發者可以登錄Hugging Face,打開TEN Agent Demo,進行模型測試和評估。這一開源舉措,不僅為開發者提供了高質量的語音處理工具,也推動了對話式AI技術的進一步發展。