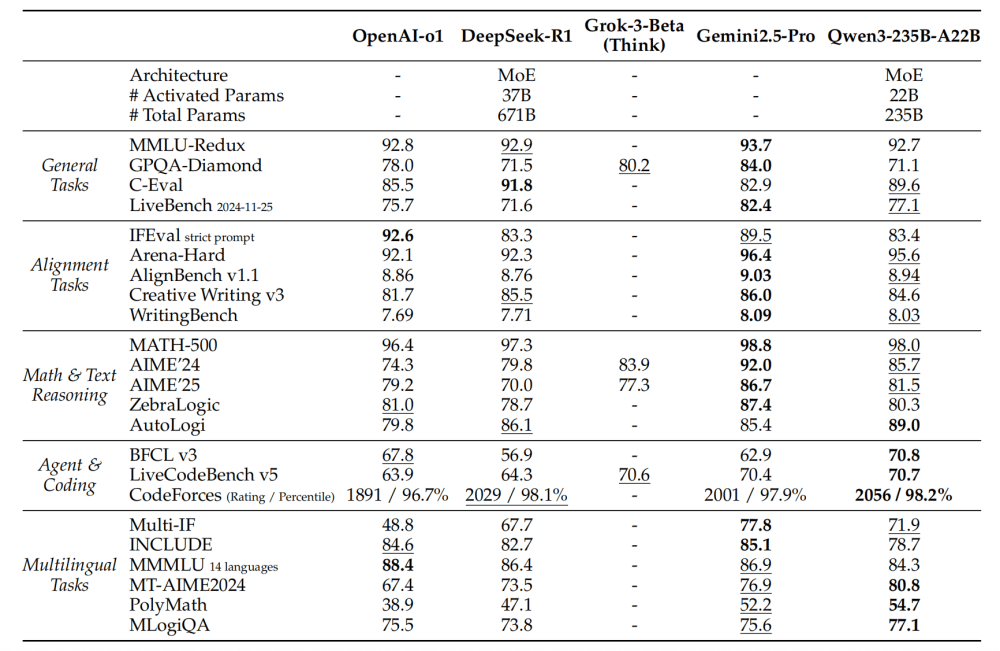
近日,阿里巴巴正式揭曉了其新一代大模型Qwen3系列的技術細節,通過一份詳盡的技術報告,向公眾展示了該系列模型的混合推理架構、獨特的訓練策略以及令人矚目的評測成績。報告顯示,Qwen3系列的旗艦模型Qwen3-235B-A22B在數學推理、代碼生成等多個核心評測領域,超越了包括DeepSeek-R1和Grok-3在內的國際頂尖模型。
Qwen3系列大模型于4月29日正式發布,涵蓋了6款稠密模型和2款MoE模型,參數規模從0.6B到235B不等。其中,旗艦模型Qwen3-235B-A22B憑借22B的激活參數,實現了235B的總參數量,并在編程、數學推理等基準測試中表現出色,超越了全球多個頂尖模型。
Qwen3系列的核心創新在于其雙系統推理架構。面對復雜的數學證明、代碼生成等任務時,模型會啟動“慢思考”深度推理模塊,支持高達38K token的動態思考預算,進行多步驟邏輯鏈分析。而在日常對話場景下,模型則以“快思考”模式運行,僅需激活20%的參數,從而實現了60%的響應速度提升和40%的算力消耗降低。
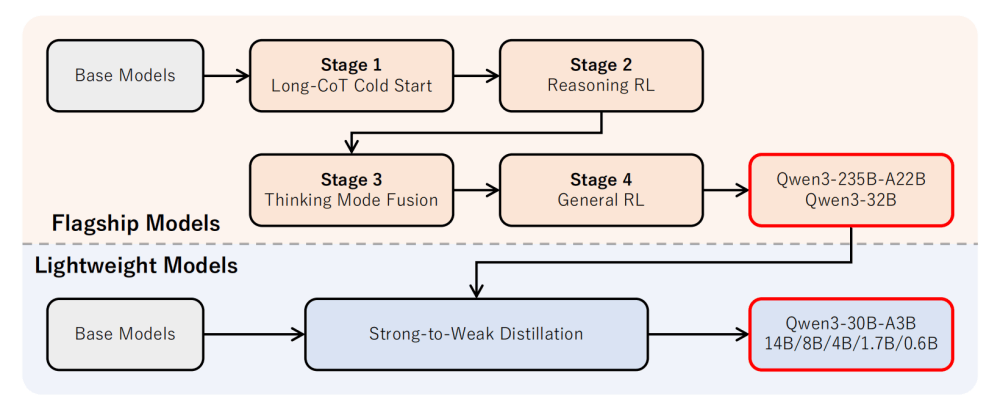
Qwen3系列模型的后訓練流程設計圍繞兩大核心目標:一是“思考控制”,通過集成“非思考”與“思考”兩種模式,用戶可以根據需求靈活選擇模型是否進行推理,并通過指定token預算來控制思考深度;二是“慢思考”,旨在簡化和優化輕量級模型的后訓練過程,借助大規模模型的知識,大幅降低構建小規模模型所需的計算成本和工作量。
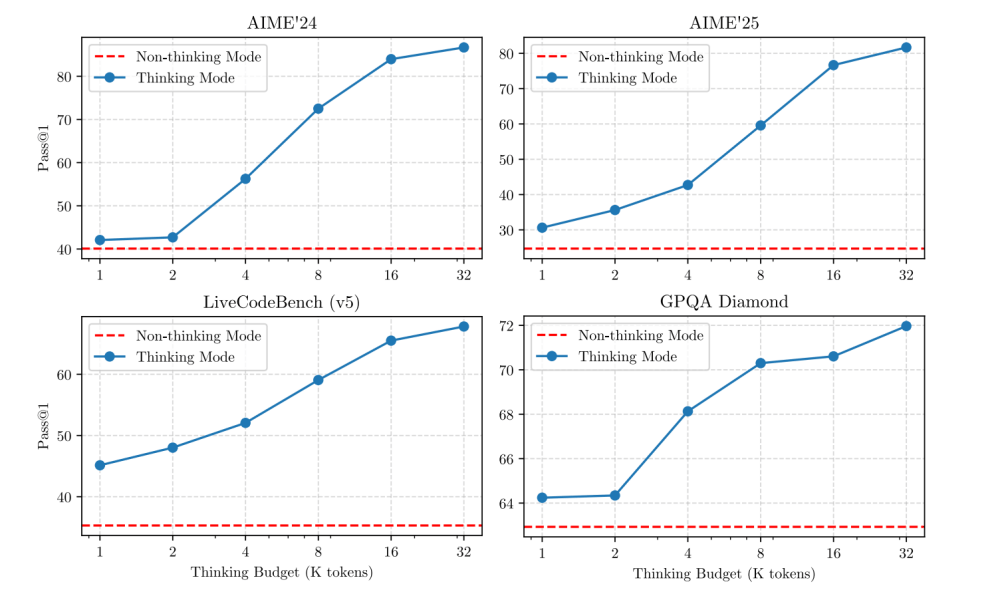
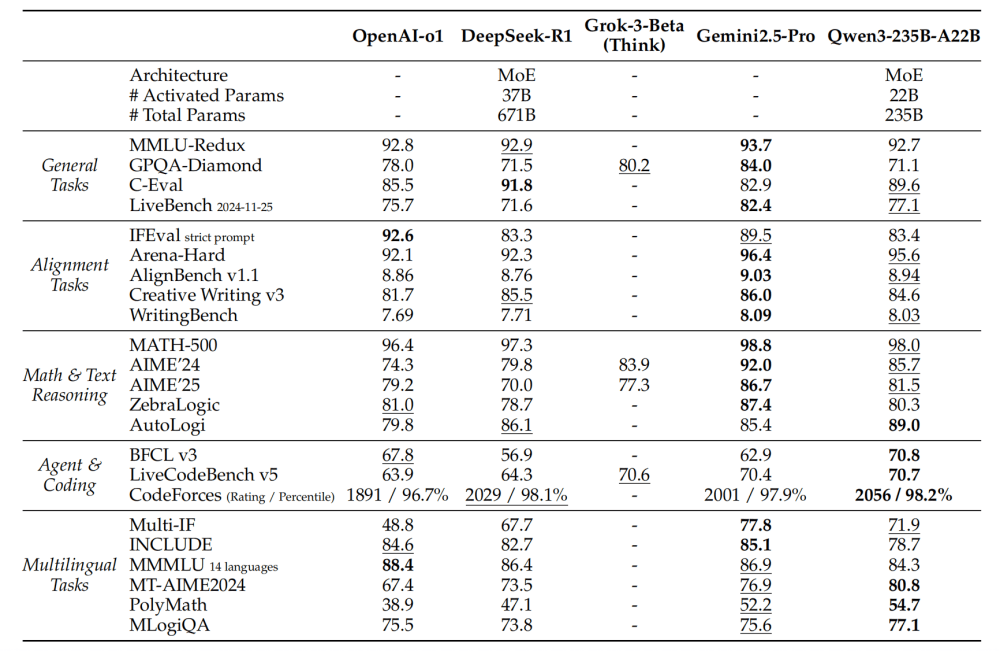
在性能評測方面,旗艦模型Qwen3-235B-A22B表現出色。在數學推理的AIME25奧數測評中,該模型獲得了81.5分的高分,刷新了開源模型的紀錄,遠超DeepSeek-R1等頂尖模型。在代碼生成的LiveCodeBench評測中,Qwen3-235B-A22B同樣表現出色,得分超過70分,超越了Grok-3-Beta和DeepSeek-R1等主流模型。
Qwen3系列模型還支持跨模態任務,集成了視覺(Qwen3-VL)和音頻(Qwen3-Audio)模塊,能夠應用于醫學影像分析等領域。在硬件與效率優化方面,MoE模型采用動態激活專家策略,僅需4張H20加速卡便能實現235B旗艦模型的部署。Qwen3系列模型在參數效率、推理成本、多語言支持及AI Agent開發等多個維度均展現出顯著優勢。
Qwen3-235B-A22B于今年5月6日成功登頂國際權威大模型測評榜LiveBench開源大模型性能的榜首,進一步證明了其卓越的性能和實力。Qwen3系列模型通過混合推理架構與高效訓練策略,樹立了開源模型的新標桿,正在逐步縮小與頂尖閉源產品的差距。